
VOICE-Homepage: http://de.os2voice.org
Inhaltsverzeichnis
< Vorherige Seite | Nächste Seite >
Artikelverzeichnis
|
VOICE-Homepage: http://de.os2voice.org |
April 2004
Inhaltsverzeichnis
|
| Von Thomas Klein © April 2004 |
Der heutige Artikel ist vorerst der letzte, der sich mit REXX alleine beschäftigt. Mittlerweile sollten Sie ein wenig mehr darüber wissen, wie REXX funktioniert und was man damit alles erreichen kann. Wir werden heute einen Blick auf die wichtigsten und am häufigsten verwendeten Funktionen werfen. Die nächsten Artikel unserer Serie werden sich dann wieder mit DrDialog beschäftigen. Einige REXX-bezogene Themen werden wir noch im Rahmen von DrDialog besprechen, wie beispielsweise die grundlegenden Funktionen der Datei-Ein/Ausgabe oder bestimmte Bereiche der PARSE-Funktion. Wenn es die Zeit erlaubt und Interesse daran besteht, werde ich 'Sonderausgaben' zu den Themen PARSE, Stream-Verarbeitung und den weiteren Dingen beisteuern, die wir bis dahin nicht besprochen haben. Jedoch ist meine eigentliche Absicht, daß wir gemeinsam eine größere Beispielanwendung mit DrDialog erstellen und daher werden wir das Thema 'REXX pur' mit der heutigen Ausgabe abschließen.
Sie werden hier keine vollständige Besprechung aller REXX-Funktionen finden und natürlich gibt es zu den einzelnen Themen noch einiges mehr zu sagen, aber das würde den Rahmen sprengen. Daher werde ich im Folgenden die Funktionen vorstellen, die Sie in Ihren Programmen am häufigsten verwenden werden, bzw. die fester Bestandteil bei der Lösung gängiger Programmieraufgaben sind.
DATE und TIME
Obwohl diese beiden Funktionen meist nur dazu eingesetzt werden, das aktuelle Datum bzw. die
aktuelle Zeit zu ermitteln, kann die Funktion TIME auch als Stoppuhr verwendet werden... aber dazu
kommen wir gleich - schauen wir uns erst einmal die Syntax der Funktion DATE an:
ergebnis = DATE( [ option ] )
Hier die Kurzfassung: Wenn Sie DATE ohne Optionen aufrufen, wird das aktuelle Datum im Format TT MMM JJJJ in das Feld 'ergebnis' gestellt (wobei MMM die ersten drei Buchstaben des englischen Monatsnamens repräsentiert). Am 4. Juli 2004 würde das also 04 Jul 2004 ergeben. (Beachten Sie die Leerstellen zwischen den Datumsteilen.) Während das noch relativ 'gut' für's menschliche Auge wirkt, ist dieses Format nicht gerade geeignet, um für Sortierungen oder als Bestandteil eines Datei- oder Verzeichnisnamens verwendet zu werden. Außerdem wird in anderen Gegenden der Erde auch ein anderes Datumsformat verwendet. Und somit kommen nun die Optionen in's Spiel:
| Option | Bedeutung / Ergebnis | Beispiel für den 27. February 2004 |
|---|---|---|
| <keine> | Aktuelles Datum als TT monatsabkürzung JJJJ | 27 Feb 2004 |
| normal | Aktuelles Datum als TT monatsabkürzung JJJJ | 27 Feb 2004 |
| basedate | Anzahl vergangener Tage seit dem 1. Januar 0001 | 731637 |
| ordered | Aktuelles Datum als JJ/MM/TT | 04/02/27 |
| sorted | Aktuelles Datum als JJJJMMTT | 20040227 |
| USA | Aktuelles Datum als MM/TT/JJ | 02/27/04 |
| european | Aktuelles Datum als TT/MM/JJ | 27/02/04 |
| language | Aktuelles Datum gemäß Ländereinstellung; Standard: TT monatsname JJJJ | 27 February 2004 |
| days | Anzahl vergangener Tage seit Jahresbeginn (1. Januar) | 58 |
| month | Vollständiger englischer Name des aktuellen Monats | February |
| weekday | Vollständiger englischer Name des aktuellen Wochentags | Friday |
Beachten Sie, daß bereits die Angabe des ersten Buchstaben einer Option genügt und die Groß- / Kleinschreibung keine Rolle spielt (man kann also 'Sorted', 'S', 's', 'sORted' usw. verwenden). Außerdem muß man die Option auch nicht in Anführungszeichen angeben.
Das sind schon relativ viele Optionen für eine eher simple Funktion. Leider ist es nicht möglich, der Funktion ein Datum zu übergeben, das verwendet werden soll - es wird grundsätzlich das aktuelle Systemdatum verwendet. Wenn Sie also Datumsberechnungen oder benutzerspezifische Datumsformate benötigen, sollten Sie sich unbedingt 'datergf' von Ronny G. Flatscher anschauen, welches frei erhältlich ist (bspw. über Hobbes). Hierbei handelt es sich um ein REXX-Skript (keine DLL), die nahezu jede Art von Datumsalgorithmen unterstützt, die man sich vorstellen kann... wie z.B.:
und einiges mehr, dazu der Umfang der DATE-Funktion und alles unter Berücksichtigung von Schaltjahren... ein absolut unabdingbares Werkzeug, wenn man in REXX mit Daten herumhantieren will.
Zeit für TIME
Die Funktion TIME funktioniert ähnlich dem, was wir oben über die DATE-Funktion gelernt haben. Es wird
lediglich ein (wahlfreier) Parameter 'option' verwendet. Neben dem Ermitteln der aktuellen Systemzeit und
der Ausgabe in unterschiedlichen Formaten bietet TIME aber auch eine relativ einfach zu bedienende
Stoppuhr-Funktionalität. Zunächst schauen wir uns einmal die Syntax und eine Erläuterung der Optionen
an:
ergebnis = TIME( [ option ] )
Und noch einmal die Kurzfassung: Ohne jegliche Option gibt TIME die aktuelle Systemzeit im Feld 'ergebnis' unter Verwendung des Formats HH:MM:SS auf 24-Stunden Basis zurück. Wenn man TIME in dieser Form um 16 Uhr, 17 Minuten und 32 Sekunden aufrufen würde, erhielte man 16:17:32. Auch hier kann mittels der Optionen ein anderes Format für die Rückgabe bestimmt werden, um anderen Zeitformaten oder Problemstellungen Genüge zu tun:
| Option | Bedeutung / Ergebnis | Beispiel für 16:17 Uhr und 32 Sekunden |
|---|---|---|
| <keine> | Aktuelle Zeit als HH:MM:SS | 16:17:32 |
| normal | Aktuelle Zeit als HH:MM:SS | 16:17:32 |
| civil | Aktuelle Zeit als HH:MM (pm|am) | 4:17pm |
| long | Aktuelle Zeit als HH:MM:SS.hh0000 (hh sind dabei die hundertstel Sekunden) | 16:17:32.450000 (32 sek. und bspw. 45 hundertstel) |
| hours | Anzahl der aktuell seit Mitternacht vergangenen Stunden | 16 |
| minutes | Anzahl der aktuell seit Mitternacht vergangenen Minuten | 977 |
| seconds | Anzahl der aktuell seit Mitternacht vergangenen Sekunden | 58652 |
Wissen Sie noch, was wir über die Schreibweise für die Optionen der Funktion DATE sagten? Hier trifft
das auch wieder zu: Sie brauchen lediglich den ersten Buchstaben der Option anzugeben und die Groß- /
Kleinschreibung ist unerheblich. Aber halt - es fehlen noch zwei Optionen... nämlich die, mit denen man die
Eingangs besprochene Stoppuhr von TIME steuern kann:
| Option | Bedeutung / Ergebnis | Beispiel für 16:17 Uhr und 32 Sekunden |
|---|---|---|
| elapsed | Anzahl der Sekunden und Hundertstelsekunden die seit dem Start bzw. Zurücksetzen
des timers abgelaufen sind Format der Rückgabe ist sssssssss.hh0000 (s sind die Sekunden, hh die Hundertstel ) |
beim ersten Aufruf seit Systemstart: 0 ansonsten: Zeit seit Start/Zurücksetzen |
| reset | Anzahl der Sekunden und Hundertstelsekunden die seit dem Start bzw. Zurücksetzen
des timers abgelaufen sind Format der Rückgabe ist sssssssss.hh0000 (s sind die Sekunden, hh die Hundertstel ) Außerdem wird der timer zurückgesetzt |
beim ersten Aufruf seit Systemstart: 0 ansonsten: Zeit seit Start/Zurücksetzen |
Hier gibt's unter Umständen noch etwas Erklärungsbedarf...
Beim Starten des Programms wird ein interner Timer (Zeitgeber) auf 0 gesetzt und bleibt gestoppt. Der
erste "Stoppuhr-Aufruf" an die time Funktion (egal ob "elapsed" oder
"reset") gibt lediglich 0 zurück und startet den internen timer. Jeder nun folgende Aufruf gibt
die abgelaufene Zeit seit dem Starten des Timers zurück. Während bei "elapsed" lediglich die
Ermittlung der abgelaufenen Zeit stattfindet, wird der Timer bei "reset" zusätzlich danach auf
0 (null) zurückgesetzt.
Beispiel:
| Uhrzeit | Ereignis | Ergebnis |
|---|---|---|
| 09:02:58 | Computer wurde gestartet | timer ist aus |
| 09:17:15 .00 | time("e") wird aufgerufen | time() gibt zurück: 0 timer ist gestartet |
| 09:17:25 .75 | time("e") wird aufgerufen | time() gibt zurück: 10.750000 |
| 09:17:35 .75 | time("r") wird aufgerufen | time() gibt zurück: 20.750000 timer wird auf 0 zurückgesetzt |
| 09:17:45 .75 | time("e") wird aufgerufen | time() gibt zurück: 10.000000 |
Es existiert übrigens kein Aufruf, mit dem man den internen Timer stoppen kann. Der Timer läuft und läuft und läuft also... entweder, bis er zurückgesetzt, das Programm neu gestartet wurde oder die Anzahl der abgelaufenen Sekunden einen Wert erreicht, der größer als 999999999.990000 ist - was ungefähr 31,7 Jahren entspricht. Das würde mich persönlich nicht kratzen oder irgendwie beunruhigen, wenn wir alle Windows-Anwender wären, denn ein Windows-Rechner, der 31,7 Jahre am Stück läuft? Ach was! Diese Dinger müssen ja ohnehin alle Nase lang neu gestartet werden, spätestens nach zwei Jahren, um eine neue Version zu installieren... aber hallo: Wir reden von OS/2. Also seien Sie vorsichtig, wenn Sie den Timer starten und Ihr Programm weiter laufen lassen... ;-)
filespec
Diese Funktion ist ziemlich nützlich, wenn man mit Laufwerksbuchstaben, Datei- und Verzeichnisnamen
herumhantieren muß. Für einen angegebenen Dateinamen werden (je nach Option) der
Laufwerksbuchstabe, die Verzeichniskette oder der Dateiname inklusive Erweiterung (sofern enthalten)
zurückgegeben. Hier die Syntax:
ergebnis = FILESPEC( option , <dateiangabe> )
Option ist dabei entweder "drive" (Laufwerksbuchstabe), "path" (Verzeichnis) oder "name" (Dateiname) inklusive der Anführungszeichen. Auch hier gilt, daß die Option auf den ersten Buchstaben abgekürzt werden kann wie z.B. in
SAY FILESPEC( "p", meindateiname )
Im Vergleich zu den meisten von Hand codierten Funktionen zum Aufteilen von Dateiangaben kann
FILESPEC auch perfekt mit "besonderen" Dateiangaben umgehen. Das betrifft
beispielsweise UNC-Namen (die einen führenden doppelten backslash enthalten) als auch Datei- und
Verzeichnisnamen, die Leerstellen enthalten. Für Dateien, die sich im Wurzelverzeichnis eines Laufwerks
befinden wie z.B. "c:\datei" wird tatsächlich das Verzeichnis "\" zurückgegeben
anstelle von beispielsweise <nichts> oder "\datei". ;-) Wenn Sie einmal versucht haben,
eine solche Funktion von Hand zu codieren, werden Sie bestimmt den einen oder anderen Stolperstein
kennen, den so etwas mit sich bringt... und sie werden filespec mögen.
directory
Ohne zusätzlichen Parameter ermittelt man damit das aktuelle Verzeichnis:
say directory()
oder
aktverz = directory()
Optional können Sie auch das aktuelle Verzeichnis wechseln, indem Sie das Zielverzeichnis als
Parameter angeben. directory() wechselt dann zunächst in das angegebene Verzeichnis
und gibt dieses dann direkt zurück, falls der Wechsel erfolgreich war (das Verzeichnis also existierte):
neuverz = directory("\mmos2")
say neuverz
Wenn in das angegebene Verzeichnis gewechselt werden konnte, wird dessen Name von der Funktion
zurückgegeben.
Übrigens unterstützt directory() im Gegensatz zum simplen Befehl "CD"
die Angabe von Laufwerksbuchstaben in der Verzeichnisangabe - Sie müssen dafür also nicht
zuerst das Laufwerk wechseln.
Beachten Sie auch, daß directory() nach dem Wechsel des Verzeichnisses dessen Name so
zurückgibt "wie er lautet", sondern genau so, wie Sie ihn angegeben haben:
say directory("c:\MPtn\dLl")
würde ausgeben c:\MPtn\dLl (sofern das Verzeichnis existiert), anstelle des möglichen
"echten" Namens C:\mptn\DLL. Somit können Sie directory() auch
sehr leicht einsetzen um zu prüfen, ob ein Verzeichnis vorhanden ist, indem Sie den Rückgabewert ohne
zusätzliche Prüfung von Groß/Kleinschreibung usw. mit dem Namen vergleichen, den Sie angegeben haben.
Selbstverständlich gibt es noch andere (auch elegantere) Methoden, eine solche Prüfung zu kodieren, aber
hier geht's erst mal um ein Beispiel (wenn Sie das selbst nachtippen wollen, lassen Sie die Zeilennummern
weg: Diese dienen nur zur Referenz für die Erläuterungen weiter unten):
1 aktverz = directory() 2 neuverz = "S:\OS2Image\SomeDir" 3 if directory(neuverz) = neuverz then 4 say "Verzeichnis existiert" 5 else 6 say "Verzeichnis nicht vorhanden" 7 call directory(aktverz)
Zeile 1 ermittelt das aktuelle Verzeichnis, damit nach einem erfolgreichen Verzeichniswechsel dorthin
zurückgekehrt werden kann. In Zeile 2 wird das Verzeichnis, dessen Existenz geprüft werden soll, in einer
Variablen namens 'neuverz' gespeichert. Die Zeilen 3 bis 6 stellen die eigentliche Prüfung
dar mit dem Aufruf der Funktion directory() in Zeile 3 und der Prüfung, ob das neue
Verzeichnis mit unserer Vorgabe übereinstimmt. Die letzte Zeile (7) wechselt dann zurück in das zu Beginn
aktuelle Verzeichnis. Außerdem zeigt sich wieder einmal, wie man eine Funktion auch per "call"
verwenden kann, wenn man kein Interesse am Rückgabewert hat.
Eigentlich bräuchten wir den Rückwechsel in das zu Beginn aktuelle Verzeichnis nur dann vorzunehmen,
wenn der Wechsel erfolgreich war, denn ansonsten (wenn neuverz nicht existiert),
würden wir uns nach wie vor im ursprünglichen aktuellen Verzeichnis befinden. Aber hey - Optimierung
ist etwas für fortgeschrittene REXX-Programmierer und wir befinden uns hier in einem Einsteigerkurs. ;-)
Eine letzte Bemerkung: Stellen Sie sicher, daß Sie keinen abschließenden Backslash im Verzeichnisnamen
verwenden, denn so etwas kann directory() nicht leiden. In dieser Hinsicht verhält sich
directory() auch nicht wie der "CD"-Befehl, dem es ganz egal ist,
ob ein abschließender Backslash vorhanden ist oder nicht...
value
...wird verwendet, um den Wert einer Variablen zu ermitteln. Dies betrifft sowohl Variablen der
REXX-Umgebung (Ihr Programm zum Beispiel) als auch die von OS/2 selbst. Im letzteren Fall wertet
value() sogenannte Umgebungsvariablen aus. Eine Umgebungsvariable ist im
Prinzip das, was man mit einer Anweisung im Format SET <variable> = <wert> in
der Datei CONFIG.SYS bewerkstelligt. Aber schauen wir uns zunächst die Syntax an:
ergebnis = VALUE( <symbol> , [neuwert], [<umgebung>] )
Fein - der Parameter neuwert ist optional. Das bedeutet, daß, wenn Sie den Wert eines
Symbols (einer Variablen) nicht ändern wollen, Sie diesen Parameter einfach weglassen. Der Parameter
<umgebung> teilt der value-Funktion mit, in welcher Umgebung nach der
Variablen "gesucht" werden soll. Wenn dieser Parameter ausgelassen wurde, bezieht sich die
value()-Funktion auf die REXX-Umgebung. Wenn "os2environment" als Parameter
verwendet wurde, wird eine entsprechende OS/2-Umgebungsvariable ausgewertet. Schauen Sie sich einmal
das folgende Stück code an, um dem Ganzen folgen zu können:
/* REXX-Code-Beispiel */
path = "C:\Programme\Eigene\Rexx\Beispiel1"
say value("path")
say value("path",,"os2environment")
Wie im obigen Beispiel dargestellt könnte auch in Ihrem Programm eine Variable namens
"path" existieren, in der Sie für einen bestimmten Zweck einen Verzeichnisnamen
speichern. Wie Sie vielleicht wissen, gibt es in OS/2 selbst auch eine Umgebungsvariable mit dem Namen
"path", die verwendet wird, um eine ausführbare Datei zu suchen, falls diese sich nicht im
aktuellen Verzeichnis befindet. Die erste der beiden say-Anweisungen im obigen Beispiel
ermittelt den Wert der programminternen "path"-Variable und gibt daher aus
C:\Programme\Eigene\Rexx\Beispiel1. Die zweite say-Anweisung verwendet
allerdings die OS/2-Umgebung, um Variable und Wert zu bestimmen, und gibt daher den Inhalt der
OS/2-Umgebungsvariablen "path" aus... was dann in etwa so aussieht wie
C:\MPTN\BIN;C:\IBMCOM;C:\OS2\emx\bin;C:\IBMLAN\NETPROG;C:\MUGLIB;.... und so weiter,
je nach dem, wie eben Ihr Systempfad aussieht.
Wie Sie sich wahrscheinlich jetzt vorstellen können, ist es mit value() möglich, die Inhalte
von Umgebungsvariablen zu ändern, indem man den Parameter "os2environment" angibt und
dazu noch den gewünschten neuwert. Ja, das kann man - wenn Sie dieses Thema aber
interessiert, sollten Sie sich unbedingt einmal die beiden Funktionen SETLOCAL und
ENDLOCAL anschauen (die wir hier nicht besprechen werden). Die Verwendung beider
Funktionen ist übrigens auch im Beispiel zur VALUE()-Funktion abgebildet, das Sie in der
Hilfedatei rexx.inf finden.
Vielleicht fragen Sie sich jetzt, warum Sie den Wert einer Variablen in Ihrem REXX-Programms relativ
umständlich mittels value() ermitteln sollten. Der Knackpunkt ist, daß value()
nicht einfach den Namen einer Variablen verwendet, sondern das ganze vielmehr als einen Ausdruck
behandelt und dessen Ergebnis dann verwendet. Schauen Sie sich dazu das folgende Beispiel an:
/* noch ein REXX-Code-Beispiel */ xyz = "Das ist der Inhalt der Variable 'xyz'..." meinevariable = "xyz"
Wenn Sie nun codieren würden
say meinevariable
dann würde ausgegeben/p>
xyz
Nun gut - nichts besonderes. Aber... würden Sie stattdessen schreiben
say value(meinevariable)
würde dafür ausgegeben
Das ist der Inhalt der Variable 'xyz'...
denn value() würde zunächst den Inhalt von meinevariable ermitteln
(also xyz) und dann den Inhalt der Variable namens xyz. Aber passen Sie auf, denn wenn
Sie an dieser Stelle folgendes angeben würden (beachten Sie die Anführungszeichen!):
say value("meinevariable")
würde schlichtweg nur ausgegeben
meinevariable
Warum? Weil Sie ein Literal angegeben haben (durch Verwendung der Anführungszeichen) anstelle einer Variablen. Verstanden? ;-)
random
Das ist die Funktion Ihrer Wahl, wenn Sie ein Spiel in REXX programmieren möchten. Übergeben Sie einfach
einen Mindest- und einen Maximalwert, und Sie erhalten eine Zufallszahl, die sich genau in diesem Bereich
befindet. Um zum Beispiel eine zufällige Augenzahl eines Würfels zu simulieren, brauchen Sie lediglich die
folgende Anweisung zu verwenden:
wuerfelwert = random(1,6)
Klasse, oder? Aber diese Funktion birgt noch etwas viel interessanteres in sich. Eine Basiszahl, die zur
Ermittlung der Zufallszahlen verwendet werden kann. Um zu verstehen wofür das nun wieder gut sein
soll und was es damit auf sich hat, schlage ich Ihnen vor, einmal Mahjongg zu starten. Sie
wissen ja, daß die Positionen der Spielsteine hier zufällig ermittelt werden? Gut. Aber jetzt probieren Sie
'mal folgendes: Starten Sie ein neues Spiel, aber wählen Sie es gezielt anhand einer beliebigen
Spielnummer aus. Schauen Sie sich die Positionen einiger Spielsteine an, starten Sie ein anderes Spiel und
starten Sie nun nochmals ein Spiel mittels der Spielnummer, die Sie vorhin angegeben hatten: Die Positionen
der Steine stimmen exakt überein. Wie machen die das? Verwenden die da irgendwo eine Liste mit
vorgegebenen Positionen? Neeee... die verwenden einfach den Basiszahl-"Trick":
Wenn Sie keine Basiszahl angeben, wird die Zufallszahl jedes mal wirklich zufällig ermittelt. Wenn
Sie aber eine Basiszahl angeben, erfolgt die Berechnung aller folgenden Zufallszahlen vielmehr
mathematisch, so daß damit eine vorhersagbare (oder sagen wir besser "reproduzierbare") Folge
von Zufallszahlen entsteht. Beispiel:
/* random mit Basiszahl */ basis=45678 sequenz="" sequenz = random(1,6,basis) do 69 sequenz = sequenz || random(1,6) end say sequenz
Kopieren Sie das obige Beispiel in ein leeres Editorfenster, und speichern Sie es als
randtest.cmd (und geben sie ggf. plain-text als Format an). Starten Sie dann das Skript.
Dann nochmals. Und nochmals. Es wird eine zufällige Reihenfolge von Ziffern im Bereich 1 bis 6 ausgegeben.
Aber die Reihenfolge ist immer gleich. Das liegt an der Basiszahl. Testweise können Sie jetzt noch den
Parameter basis aus dem ersten random-Aufruf entfernen, so daß dieser dann lautet
sequenz = random(1,6)
(also so wie der Folgeaufruf) und lassen das Skript dann nochmals mehrmalig laufen. Jetzt werden
immer unterschiedliche Reihenfolgen ausgegeben. Sobald Sie einmal eine Basiszahl in Ihrem Programm
verwendet haben, werden alle Folgeaufrufe von random anhand der Basiszahl
durchgeführt, bis Sie eine andere Basiszahl verwenden (die selber natürlich eine Zufallszahl sein kann).
Was das obige Programm eigentlich macht: Zunächst wird ein leerer String (eine Zeichenkette) namens
("sequenz") definiert, die dann den Zufallswert aus dem ersten Aufruf von
random zugewiesen bekommt. Das folgende do generiert weitere 69
Zufallszahlen (diesmal ohne Angabe einer Basiszahl), die eine nach der anderen an den String angehängt
werden. Dieser wird am Ende ausgegeben. Und hier noch das Syntaxdiagramm von random:
syntax 1: ergebnis = RANDOM( <min>, <max>, [<basis>] )
syntax 2: ergebnis = RANDOM( <max>, [<basis>] )
Im zweiten Syntaxschema wird für das fehlende min intern der Wert null verwendet.
Somit sind die beiden folgenden Anweisungen in Ihrer Bedeutung identisch:
ergebnis = RANDOM(100) ergebnis = RANDOM(0,100)
Es gibt viele Gründe, warum REXX eine unglaublich vielseitige Programmiersprache ist. Einer der
wichtigsten ist meiner Meinung nach, daß die Fähigkeiten von REXX sich leicht durch externe Bibliotheken
(Libraries) erweitern lassen. Es gibt eine Vielzahl an Funktionsbibliotheken für REXX unter OS/2, für nahezu
jeden erdenklichen Einsatzzweck - und die meisten davon sind kostenlos. Und es gibt eine Bibliothek, die
von Anfang an mit OS/2 (oder eComStation) installiert wird: rexxutil.dll.
Rexxutil stellt diverse Funktionen zur Verfügung, von denen wir hier allerdings nur einen Teil
besprechen werden: Nämlich die, die Sie am meisten verwenden werden.
Um in REXX Funktionen verwenden zu können, die sich in externen Bibliotheken befinden, muß man sie
zunächst "laden" (damit sie in REXX zur Verfügung stehen). Bevor wir im Detail weitermachen,
hier eine kurze Einführung zum Thema "Funktionsbibliotheken": Bibliotheken (die für gewöhnlich
die Erweiterung ".DLL" verwenden) enthalten eine oder mehrere Funktionen und
darüber hinaus oft auch weitere Ressourcen wie Texte, Grafiken und so weiter. Programme verwenden im
Prinzip eigentlich keine Bibliotheken, sondern - um genau zu sein - Funktionen oder Ressourcen, die sich in
Bibliotheken befinden. Dies bewirkt eine Anforderung, die Bibliothek zu laden. Solche Anforderungen
werden zwar von Programmen ausgelöst, jedoch vom Betriebssystem bearbeitet und verwaltet. Dieses
Verfahren ermöglicht es dem Betriebssystem, eine Bibliothek nur einmal laden zu müssen, wenn mehrere
unterschiedliche Programme diese anfordern: Wenn die Bibliothek bereits geladen wurde, wird sie bei einer
erneuten Anforderung durch ein anderes Programm nicht erneut geladen. Vielmehr wird dem Programm
dann eine "Instanz" der Bibliothek zur Verfügung gestellt. Eine Instanz ist in diesem
Zusammenhang ein für jedes Programm individueller Speicherbereich, der die Daten aufnimmt, die zwischen
dem jeweiligen Programm und der Bibliothek ausgetauscht werden. Aus Sicht des Betriebssystems kann
man sich das so vorstellen, daß eine Bibliothek aus einem "Stamm" besteht, der die Funktionen
und Ressourcen enthält und einer... ähm... nennen wir's "Dateninstanz", die für jede Anforderung
(also die Programme) erzeugt wird. Die Idee bei diesem Verfahren ist, daß Speicher- und Rechnerkapazität
damit gespart werden, da der Bibliotheks-"Stamm" nur einmal geladen werden muß. Die für
jedes Programm individuellen Statuswerte und Daten werden in der "Dateninstanz" abgelegt.
Wenn nun fünf Programme laufen, die alle eine bestimmte Biblitohek verwenden (weil sie irgendeine
Funktion oder Ressource darin benutzen), wird der Bibliotheksstamm nur einmal geladen und es werden fünf
Dateninstanzen erstellt - anstatt das komplette Gebilde fünf mal zu laden (was dann so viel Speicherplatz
benötigen würde wie 5-mal Bibliotheksstamm plus 5-mal Dateninstanz).
Aber gut, kommen wir zurück zum Thema: Funktionen aus Bibliotheken laden. REXX enthält eingebaute Funktionen, um mit externen Funktionen zu arbeiten:
RxFuncAdd
Lädt eine Funktion aus einer externen Biblitohek.
ergebnis = RXFUNCADD(<mein-funktionsname>,<dll-name>,<dll-funktionsname>)
Das <ergebnis> ist ein Rückkehrcode, der angibt, ob die Funktion erfolgreich geladen wurde oder
nicht. Code 0 (null) bedeutet, daß es geklappt hat, alles andere bedeutet, daß etwas schiefging. Während
der <dll-name> der Name der externen Bibliothek ist (ohne die Erweiterung
".dll" - in unserem Fall entspräche das also 'rexxutil') gibt man mit
<dll-funktionsname> an, welche Funktion aus der Bibliothek geladen werden soll.
Dabei muß es sich um genau den Namen handeln, unter dem die jeweilige Funktion in der Bibliothek
bekannt (gespeichert) ist. Der erste Parameter <mein-funktionsname> teilt REXX mit,
unter welchem Namen Sie diese Funktion in Ihrem Programm einsetzen wollen (quasi den Namen, den Sie
in der entsprechenden CALL-Anweisung angeben). Prinzipiell sollten Sie auch hier den Namen angeben, der
für <dll-funktionsname> verwendet wird, um die Sache übersichtlich zu halten. Zwar
ist es gut zu wissen, daß man eine Funktion auch unter einem anderen als dem bibliotheksinternen Namen
laden kann, aber es verkompliziert die Sache. Der Nachteil dabei ist nämlich, daß Sie es anderen
Programmen damit erheblich erschweren zu prüfen, ob eine bestimmte Funktion bereits geladen wurde.
Verwenden Sie also besser <dll-funktionsname> auch im Parameter
<mein-funktionsname>. Das ist ein de-facto Standard in der REXX-Programmierung
und ermöglicht eine vereinfachte Prüfung (wie wir im Folgenden auch an RxFuncQuery
sehen werden).
Und wie schon so oft besprochen, müssen Sie den Rückkehrcode der Funktion (ergebnis)
nicht unbedingt verwenden (wie bei allen Funktionen in REXX) - in diesem Fall verwenden Sie dann die
folgende Schreibweise:
call RXFUNCADD <mein-funktionsname>,<dll-name>,<dll-funktionsname>
Beachten Sie auch hier wieder, daß die Parameterliste der Funktion bei dieser Schreibweise nicht in Klammern eingeschlossen wird.
RxFuncDrop
Entlädt eine zuvor geladene Funktion wieder. Tatsächlich wird damit nur die Instanz entladen und das
Betriebssystem entlädt dann die Bibliothek selbst, wenn kein weiteres Programm diese mehr benötigt...
result = RXFUNCDROP(<mein-funktionsname>)
Was wir oben bereits über den Rückkehrcode von RxFuncAdd gesagt haben, trifft auch
auf RxFuncDrop zu. Null bedeutet "alles klar", alles andere bedeutet Probleme.
Beachten Sie, daß Sie als Funktionsnamen hier dasselbe angeben müssen, was Sie beim Laden der Funktion
mit RxLoadFunc im gleichen Parameter <mein-funktionsname>
angegeben hatten.
RxFuncQuery
Viele Leute werden Ihnen sagen, daß Sie zur Erhöhung von Leistung und Stabilität vor dem Laden einer
Funktion prüfen sollten, ob diese nicht bereits geladen wurde und - im Gegenzug - vor dem Beenden des
Programms die geladenen Funktionen nicht wieder zu entladen, sofern das vorherige Laden nicht nötig war.
Diese Prüfung bewerkstelligen Sie mit RxFuncQuery: Hiermit prüft man, ob eine externe
Funktion bereits "woanders" geladen wurde. Wir besprechen diese Funktion, ja, aber lassen Sie
mich Ihnen sagen, daß ich das für "fortgeschrittenes" Wissen halte, das wir erst einmal ruhig
unter den Tisch fallen lassen können. Wenn Sie so weit mit REXX klar kommen, daß Sie sonst keine
Probleme mehr haben, können Sie sich getrost auch um solche Sachen kümmern. ;)
Wie dem auch sei - hier ist die Syntax:
ergebnis = RXFUNCQUERY(<name>)
Wenn eine Funktion durch ein Programm registriert (geladen) wurde, wird der damit verbundene
<mein-funktionsname> quasi aufgenommen in eine von allen REXX-Programmen
gemeinsam verwendete Funktionsliste. Die Programme können über diese Liste prüfen, ob eine Funktion
von "jemand anderem" bereits geladen wurde und sich dann die Arbeit sparen, die Funktion
selber laden zu müssen. Hier kommen wir jetzt wieder zum Knackpunkt beim Thema Funktionsnamen:
Wenn Sie eine Funktion mit einem beliebigen, abweichenden Namen laden (also einem anderen als dem
DLL-internen Namen), können andere Programme nicht mehr ohne weiteres ermitteln, ob eine bestimmte
Funktion bereits geladen wurde. Aber ein größeres Problem ist, daß der von Ihnen "ausgedachte"
Name unter Umständen von einer anderen Funktion in einem anderen Programm verwendet wird. Wenn
dieses Programm dann gestartet wird und prüft, ob "seine" Funktion bereits geladen wurde,
könnte es annehmen, daß dies der Fall sei und versuchen, mit "Ihrer" Funktion zu arbeiten, die
dann aber völlig von dem abweicht, was das andere Programm erwartet und... ups. Darum sollten Sie
Funktionen immer auch unter dem DLL-internen Namen laden.
Eine letzte Anmerkung zum Thema Funktionen: Als REXX-Einsteiger sollten Sie wissen, wie man
externe Funktionen mit RxFuncAdd lädt, und den Rest für's erste einfach vergessen. Wenn
Ihr Programm Bibliotheken bzw. Funktionen lädt, ohne vorher zu prüfen, ob diese bereits geladen wurden,
und mit oder ohne Entladen der Funktionen beendet wird, wird Ihr Rechner dadurch weder Feuer fangen
noch werden andere Programme abstürzen. Es wird einfach trotzdem funktionieren. Alles klar? Jetzt, da
wir wissen, wie man sie lädt, schauen wir uns die eigentlichen Funktionen an, die uns RexxUtil
zur Verfügung stellt. Übrigens werde ich dem jeweiligen Funktionsnamen im Folgenden "rexxutil:"
voranstellen, um klarzustellen, daß es sich dabei nicht um Funktionen handelt, die in REXX selbst vorhanden
sind (sondern vielmehr Funktionen der externen Bibliothek REXXUTIL.DLL).
rexxutil: SysLoadFuncs und SysDropFuncs
Damit werden alle Funktionen der Bibliothek REXXUTIL auf einmal geladen.
SysLoadFuncs lädt sie alle und SysDropFuncs entlädt sie wieder. Na,
vielleicht wäre ein Beispiel hier angebracht, um den Einsatzzweck zu verdeutlichen: Stellen Sie sich vor, Sie
würden in Ihrem Programm die Funktionen SysFileTree, SysFileSearch,
SysFileDelete und SysSleep benötigen, die in der Bibliothek
rexxutil enthalten sind. Dann könnten Sie die Funktionen entweder laden, indem Sie die
folgenden Anweisungen verwenden...:
rc = RxFuncAdd('SysFileTree', 'rexxutil', 'SysFileTree')
rc = RxFuncAdd('SysFileSearch', 'rexxutil', 'SysFileSearch')
rc = RxFuncAdd('SysFileDelete', 'rexxutil', 'SysFileDelete')
rc = RxFuncAdd('SysSleep', 'rexxutil', 'SysSleep')
(und Sie müssten die Funktionen auch entsprechend wieder einzeln entladen)... oder, indem Sie einfach nur folgendes angeben:
rc = RxFuncAdd('SysLoadFuncs', 'rexxutil', 'SysLoadFuncs')
call SysLoadFuncs
Und das war's schon. Alle in rexxutil.dll enthaltenen Funktionen sind dann geladen und stehen Ihnen nun zur Verfügung. Um sie alle wieder zu entladen, lautet der Aufruf entsprechend
call SysDropFuncs
und erledigt...
Beachten Sie aber, daß SysLoadFuncs zwar alle Funktionen aus rexxutil lädt, selbst aber
auch zunächst erst einmal geladen werden muss!
rexxutil: SysFileTree
Keine Panik - hier werden keine Baumstrukturen für Verzeichnisse erzeugt. Es handelt sich dabei viel mehr
um eine Funktion, die ähnlich zum DIR-Befehl arbeitet und Datei- bzw. Verzeichsnamen und weitere Daten
abrufen kann. Da SysFileTree mit Platzhalterzeichen umgehen und auch rekursiv in
Unterverzeichnissen suchen kann, wird die zurückgelieferte Datenmenge unter Umständen ziemlich groß.
Aus diesem Grund werden die ermittelten Daten in einer Stammvariable übergeben.
ergebnis = SysFileTree(<muster>, <stammvar>, [option], [suchattrib], [neuattrib] )
ergebnis |
ist der Rückkehrcode des Funktionsaufrufs. Hiermit wird nur mitgeteilt, ob die Funktion aufgerufen werden konnte oder nicht. Die eigentlichen Daten werden in der Stammvariable zurückgegeben. |
muster |
ist der Datei- und/oder Verzeichnisname (mit oder ohne Platzhalter), nach dem gesucht werden soll. |
stammvar |
der Name der Variablen (eingeschlossen in Anführungszeichen), in welcher die Daten zurückgegeben werden sollen. |
option |
gibt an, wie die Funktion nach <muster> suchen soll und welche Informationen
über die gefundenen Dateien/Verzeichnisse zurückgegeben werden sollen. Es ist eine Kombination, die
aus einem oder mehreren der folgenden Buchstaben besteht: F sucht nach files, also Dateien, die <muster> entsprechen D sucht nach directories also Verzeichnissen, die <muster> entsprechen B sucht nach beiden Typen (Dateien und Verzeichnisse), die <muster> entsprechen S auch subdirectories (Unterverzeichnisse) sollen durchsucht werden T Datums- und Zeitangabe für die Dateien/Verzeichnisse werden im timestamp -Format (JJ/MM/TT/hh/mm) zurückgegeben O es wird nur der Datei- bzw. Verzeichnisname zurückgegeben (only name) anstelle der üblichen Angaben Datum, Zeit, Größe, Attribute und Name. |
suchattrib |
ist eine eine Kombination aus Zeichen für Dateiattribute, die von den zu suchenden
Dateien (muster) erfüllt sein müssen. Wenn dieser Parameter verwendet wird, werden
nur Dateien/Verzeichnisse zurückgegeben, die zu muster passen und deren Attribute
mit dem übereinstimmen, was hier angegeben wurde. (Hinweis unten beachten!) |
neuattrib |
Eine Kombination aus Dateiattributen (angegeben über bestimmte Zeichen), die auf jeden gefundenen Eintrag angewendet werden soll. (Hinweis unten beachten!) |
Hinweis:
Zusätzlich zur Suchfunktion kann mit SysFileTree auch eine Änderung der Dateiattribute
für die gefundenen Dateien/Verzeichnisse erreicht werden. Das ist aber für uns zunächst nicht von Interesse.
Wir werden SysFileTree lediglich zur Suche einsetzen. Wenn Sie an den weiteren Merkmalen
von SysFileTree interessiert sind, schauen Sie bitte den entsprechenden Abschnitt in der
Datei rexx.inf an.
So weit, so gut. Aber wie gibt man nun das Muster und die Optionen an, wenn man bestimmte Dateien
sucht... und was macht man dann mit der Stammvariablen? So geht's: Nehmen wir an, Sie wollen alle Dateien
mit der Erweiterung .DLL auf Ihrer Festplatte C: suchen, würden Sie für <muster> den
Wert "C:\*.DLL" angeben und <option> wäre dann "FS" für
Dateien ("Files") und Suche in Unterverzeichnissen ("Subdirectories").
Würden Sie stattdessen nur im Verzeichnis C:\OS2\DLL nach den .DLLs suchen wollen (und noch nicht mal
in dessen Unterverzeichnissen), müßten Sie für <muster> angeben
"C:\OS2\DLL\*.DLL" und Ihre <option> wäre dann nur "F". Als
Stammvariable können Sie einen neuen Variablennamen Ihrer Wahl angeben. Irgendwas in der Art von
quot;dateien" ist beispielsweise eine gute Idee...
returncode = SysFileTree("C:\*.DLL", "dateien", "FS")
Das wäre der Funktionsaufruf für das erste obige Beispiel. Nach Beendigung (das könnte etwas dauern
und Sie werden bemerken, wie Ihre Festplatte währenddessen arbeitet) enthält der returncode
(Rückgabewert der Funktion) entweder 0 (null), wenn der Aufruf erfolgreich war, oder einen anderen Wert,
falls ein Fehler auftrat. Die Stammvariable enthält alle gefundenen Dateien (sowie jeweils die zusätzlichen
Dateiangaben) in den einzelnen Einträgen. Außerdem wird in Eintrag Nummer 0 der Stammvariable
("dateien.0") die Anzahl der gefundenen Dateien und somit die Anzahl der in der
Stammvariablen enthaltenen Einträge abgelegt. Wenn keine Dateien gefunden wurden, oder die Funktion
nicht erfolgreich aufgerufen werden konnte, ist diese Anzahl 0 (null). Das komplette Beispielprogramm, um
alle .DLLs auf Festplatte C: zu suchen und anzuzeigen, lautet wie folgt:
/* alle .DLL auf C: suchen und ausgeben */
/* diese Zeile lädt die Funktion aus rexxutil.dll */
call RxFuncAdd 'SysFileTree', 'rexxutil', 'SysFileTree'
/* diese Zeile ruft die Funktion auf */
returncode = SysFileTree("C:\*.DLL", "dateien", "FS")
/* schleife über alle einträge der stammvariable */
do i = 1 to dateien.0
say dateien.i
end
/* --- ende beispielcode --- */
Die Einträge selbst würden dann ungefähr so aussehen (Auszug):
8/27/02 4:19p 96359 A---- C:\TCPIP\dll\TCPUNX.DLL 8/27/02 4:19p 46080 A---- C:\TCPIP\dll\tnls16.dll 9/18/01 3:52p 103540 A---- C:\TCPIP\dll\unzip.dll 8/27/02 4:19p 70255 A---- C:\TCPIP\dll\VT100.DLL 9/18/01 5:05p 64236 A---- C:\TCPIP\dll\wptelnet.dll 9/04/01 2:02p 49664 A---- C:\TCPIP\dos\bin\wftpapi.dll 8/21/00 10:44a 83817 A---- C:\TCPIP\dos\bin\winsock.dll
Das sieht auf den ersten Blick jetzt etwas "durcheinander" an. Wenn Sie eine "sortierfähige" Datums-/Zeitangabe bevorzugen, verwenden Sie einfach die Option "T" zusätzlich - der Funktionsaufruf sieht dann also so aus:
returncode = SysFileTree("C:\*.DLL", "dateien", "FST")
und die Ausgabe entsprechend:
02/08/27/16/19 41497 A---- C:\TCPIP\dll\TCPOOCSJ.DLL 01/09/18/15/13 503845 A---- C:\TCPIP\dll\TCPOOCSX.DLL 02/08/27/16/19 96359 A---- C:\TCPIP\dll\TCPUNX.DLL 02/08/27/16/19 46080 A---- C:\TCPIP\dll\tnls16.dll 01/09/18/15/52 103540 A---- C:\TCPIP\dll\unzip.dll 02/08/27/16/19 70255 A---- C:\TCPIP\dll\VT100.DLL 01/09/18/17/05 64236 A---- C:\TCPIP\dll\wptelnet.dll 01/09/04/14/02 49664 A---- C:\TCPIP\dos\bin\wftpapi.dll 00/08/21/10/44 83817 A---- C:\TCPIP\dos\bin\winsock.dll
Und wenn Sie die Datums-/Zeitangaben, Dateigröße und -Attribute nicht interessieren, verwenden Sie einfach die Option "O", wodurch der Funktionsaufruf dann lautet
returncode = SysFileTree("C:\*.DLL", "dateien", "FSO")
Und schon erhalten Sie als Ausgabe lediglich:
C:\TCPIP\dll\TCPUNX.DLL C:\TCPIP\dll\tnls16.dll C:\TCPIP\dll\unzip.dll C:\TCPIP\dll\VT100.DLL C:\TCPIP\dll\wptelnet.dll C:\TCPIP\dos\bin\wftpapi.dll C:\TCPIP\dos\bin\winsock.dll
Jetzt sollten Sie ein bestimmtes Verständnis dafür gewonnen haben, wie die Funktion arbeitet. Wenn
Sie nicht innerhalb von Unterverzeichnissen dessen suchen wollen, was Sie eventuell in <muster>
angegeben haben, lassen Sie einfach das "S" im Parameter <option> weg.
Oder wollten Sie schon immer mal eine Verzeichnisliste Ihrer Festplatte selber programmieren?
/* Verzeichnisse von C: ausgeben */
call RxFuncAdd 'SysFileTree', 'rexxutil', 'SysFileTree'
returncode = SysFileTree("C:\*", "dateien", "DSO")
do i = 1 to dateien.0
say dateien.i
end
rexxutil: SysFileSearch
Tja, der Name könnte irreführend sein. Hiermit suchen Sie nicht nach Dateien sondern vielmehr innerhalb
von Dateien nach einem angegebenen Suchbegriff. Die Funktion gibt Ihnen dann alle Zeilen der
angegebenen Datei zurück, die den Suchbegriff enthalten
ergebnis = SysFileSearch( <suchtext>, <dateiname>, <stammvar> [, option ] )
ergebnis |
ist der Rückkehrcode des Funktionsaufrufs. Hiermit wird nur mitgeteilt, ob die Funktion aufgerufen werden konnte oder nicht. Die eigentlichen Daten werden in der Stammvariable zurückgegeben. |
suchtext |
der Begriff, nach dem gesucht werden soll |
filename |
ist der name der Datei, in der gesucht werden soll (beachten Sie, daß hier keine Platzhalterzeichen unterstützt werden - Sie können also immer nur in einer Datei suchen) |
stammvar |
Der Name der Stammvariable, welche die gefundenen Zeilen aufnehmen soll. |
option |
Wird verwendet, um das Such- und Ausgabeverhalten der Funktion zu steuern und
ist eine Kombination aus den folgenden Buchstaben: C sucht unter Beachtung der Groß-/Kleinschreibung (<case>). Standardmäßig wird unabhängig von Groß-/Kleinschreibung gesucht. N weist die Funktion an, zusätzlich die ZeilenNummern innerhalb der Datei zurückzugeben. Standardmäßig werden keine Zeilennummern mit zurückgegeben. |
Für den Rückkehrcode ergebnis und die Stammvariable gilt dasselbe, was wir dazu
bereits oben bei SysFileSearch gesagt hatten. Kommen wir also ohne Umschweife direkt
zu einem kleinen Beispielprogramm:
/* alle zeilen aus config.sys ausgeben, die eine "basedev"-Anweisung enthalten */
/* inklusive der Zeilennummer aus config.sys */
/* Funktion laden */
call RxFuncAdd 'SysFileSearch', 'rexxutil', 'SysFileSearch'
/* Funktion aufrufen - wir verwenden eine Stammvariable namens "zeilen" */
returncode = SysFileSearch("basedev", "c:\config.sys", "zeilen", "N")
/* in einer schleife alle zeilen (also einträge der Stammvariable) ausgeben */
do i = 1 to zeilen.0
say zeilen.i
end
/* --- ende Beispielcode --- */
rexxutil: SysMkDir
Legt ein Verzeichnis an. Eine ziemlich simple, aber schnelle Funktion, die eine große Anzahl an Fehlern
ermitteln kann für den Fall, daß das Anlegen fehlschlägt. Die Syntax lautet:
rc = SysMkDir( <verzeichnis> )
Beachten Sie, daß SysMkDir keine verschachtelten neuen Verzeichnisse anlegen kann,
d.h. Sie können immer nur eine Ebene neu anlegen. Wenn Sie also ein neues Verzeichnis namens
"test1" anlegen wollen und darin das Unterverzeichnis "test1sub1", können Sie das
nicht als "\test1\test1sub1" direkt anlegen. Stattdessen müssen Sie das in zwei Schritten
erledigen... also beispielsweise so:
/* sysmkdir beispiel */ call rxfuncadd "sysmkdir", "rexxutil", "sysmkdir" call sysmkdir "c:\test1" call sysmkdir "c:\test1\test1sub1"
Gut, da fehlt jetzt unter Umständen noch eine Fehlerbehandlung (für den Fall, daß c:\test1 beispielsweise bereits existiert und somit nicht angelegt werden kann) also noch mal:
/* sysmkdir beispiel */
call rxfuncadd "sysmkdir", "rexxutil", "sysmkdir"
if sysmkdir("c:\test1") = 0 then
if sysmkdir("c:\test1\test1sub1") = 0 then
say "erfolgreich angelegt"
else
say "test1sub1 kann nicht angelegt werden"
else
say "test1 kann nicht angelegt werden"
Für eine Liste der möglichen Fehlercodes und -Ursachen beachten sie bitte den entsprechenden
Abschnitt in der Hilfedatei rexx.inf.
rexxutil: SysRmDir
Löscht ein Verzeichnis. Verhält sich dabei so ähnlich wie SysMkDir:
rc = SysRmDir( <verzeichnis> )
Beispiel:
/* sysrmdir beispiel */
call rxfuncadd "sysrmdir", "rexxutil", "sysrmdir"
if sysrmdir("c:\test1") = 0 then
say "löschen hat funktioniert"
else
say "test1 konnte nicht gelöscht werden"
Beachten Sie, daß ein Verzeichnis nur dann gelöscht werden kann, wenn es sich nicht um das aktuelle
Verzeichnis handelt (also Sie sich gerade darin befinden) und wenn es leer ist. Für eine Erläuterung der
möglichen Fehlersituationen verweise ich wieder auf rexx.inf.
rexxutil: SysFileDelete
Löscht eine Datei (und eben nur eine: Auch hier gibt's keine Unterstützung für Platzhalterzeichen im
Dateinamen). Es wird nur ein Parameter verwendet - der Dateiname.
ergebnis = SysFileDelete( <dateiname> )
/* einzelne Datei löschen - Beispiel */
call rxfuncadd "sysfiledelete", "rexxutil", "sysfiledelete"
if sysfiledelete("c:\temp.tst") = 0 then
say "Datei gelöscht"
else
say "temp.tst konnte nicht gelöscht werden "
/* -- Ende Beispielcode -- */
Das folgende Beispiel demonstriert, wie man SysFileTree und
SysFileDelete kombinieren kann um mehrere Dateien zu löschen. Außerdem wird
SysLoadFuncs verwendet, um die Funktionen zu laden:
/* temporäre Dateien suchen und löschen */ /* ACHTUNG: Es wird keine Löschbestätigung angefordert - mit Vorsicht benutzen! */ call rxfuncadd "sysloadfuncs", "rexxutil", "sysloadfuncs" call sysloadfuncs call SysFileTree "c:\var\temp\*.tmp", "dateien", "FO" do i = 1 to dateien.0 call SysFileDelete dateien.i end /* -- Ende Beispielcode -- */
rexxutil: SysSleep
Hält die Programmausführung für die angegebene Anzahl Sekunden an (quasi eine Wartefunktion).
Übrigens können Sie hier auch Sekundenbruchteile angeben (was aus der Erklärung in der Hilfedatei
rexx.inf nicht hervorgeht).
Verwenden Sie einfach einen Dezimalwert in "amerikanischer" Schreibweise (also mit einem
Punkt als Komma) wie beispielweise 0.1, um eine Wartedauer von einer Zehntelsekunde zu erreichen. Rein
theoretisch unterstützt die Funktion Wartezeiten bis hinunter zu 0.0000001 Sekunden, aber ich habe nicht
geprüft, ob das tatsächlich funktioniert. Außerdem sollten Sie vorsichtig sein, was die Präzision angeht, denn
die Wartefunktion gibt die Rechenzeit und Systemkapazität an andere Prozesse ab und unterliegt somit der
jeweils gerade vorliegenden Systemauslastung...
Syntax: call SysSleep <sekunden>
Ach ja: SysSleep hat keinen Rückkehrcode.
/* SysSleep Beispiel */ call rxfuncadd "syssleep", "rexxutil", "syssleep" do 5 call SysSleep 1 say "tick" end /* -- ende Beispielcode -- */
Das obige Beispiel zeigt fünf mal "tick" an, nachdem jeweils eine Sekunde vergangen ist.
rexxutil: SysIni
Mit dieser Funktion können INI-Dateien bearbeitet werden. Aber wir reden hier nicht von den typischen,
reinen Textdateien, die unter Windows geläufig sind - nee, nee: Hier geht's um OS/2, hier können die
INI-Dateien nun mal nicht mit jedem x-beliebigen Texteditor bearbeitet werden, sondern es braucht
spezielle Funktionen. Das Arbeiten mit binären INI-Dateien beinhaltet diverse Aufgaben. Schauen wir uns
dazu erst einmal an, welche Struktur eine solche INI-Datei aufweist.
INI-Dateien enthalten Anwendungen, die man sich quasi wie "Verzeichnisse" in einem
Dateibaum vorstellen kann - nur eben innerhalb der INI-Datei.
Jede Anwendung kann einen oder mehrere Schlüssel enthalten, denen ein Wert zugewiesen
ist (oder auch nicht). Schauen Sie sich den folgenden Bildschirmabzug von OS/2s eigenem
Registrierungseditor (regedit2.exe) an, der zum Bearbeiten von INI-Dateien
verwendet werden kann:
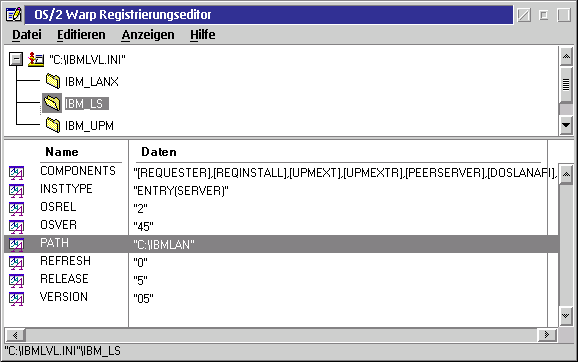
Die obige Abbildung zeigt regedit2 mit der geladenen Datei "C:\IBMLVL.INI".
Der obere Teil zeigt die in der Datein enthaltenen Anwendungen. "IBM_LS" wurde
ausgewählt und dazu werden im unteren Teil die enthaltenen Schlüssel angezeigt. Einer der
Schlüssel wurde hervorgehoben um zu verdeutlichen, wie es sich mit dem zugewiesenen Wert
verhält. Um das Thema abzuschließen, hier eine vereinfachte Darstellung der Verhältnisse in einer
INI-Datei.:
1 Ini-Datei kann N Anwendungen enthalten
1 Anwendung kann N Schlüssel enthalten.
1 Schlüssel kann 1 Wert enthalten
Die meiste Zeit werden Sie beim Arbeiten mit INI-Dateien wahrscheinlich nur damit zu tun haben,
Schlüssel und/oder Werte zu lesen oder zu schreiben. Aufgrund der Organisation einer INI-Datei stellt
die SysIni-Funktion aber auch andere Mittel zur Verfügung - beispielsweise, um alle Schlüssel
einer Anwendung aufzulisten und so weiter. Außerdem können mit SysIni sowohl
die OS/2-eigenen INI-Dateien (os2sys.ini und os2.ini) als auch eigene
(benutzerspezifische) INI-Dateien bearbeitet werden. Um der Funktion mitzuteilen, welche INI-Datei
verwendet werden soll, verwenden Sie den Parameter <inidatei> und geben darin
einen der folgenden Werte an:
os2sys.ini")os2.ini")regedit2.exe gemacht wird)Hier eine Übersicht der Arbeitsweisen der Funktion sowie der dafür benötigten Syntax und Parameter:
| Aufgabe | Syntax | Anmerkung |
|---|---|---|
| Einzelnen Schlüssel/Wert in eine Anwendung schreiben |
ergebnis = SysIni(<inidatei>, <anwendung>, <schlüssel>, <wert> ) |
- legt anwendung und/oder schlüssel an, wenn diese in der INI-Datei
nicht existieren - legt auch die INI-Datei an, falls sie noch nicht existiert - das ergebnis ist eine Zeichenkette, die entweder leer ist, wenn der Aufruf erfolgreich war oder "error:" wenn ein Fehler auftrat (zum Beispiel, wenn das Verzeichnis der INI-Datei nicht existiert) |
| einen wert aus einem schlüssel einer anwendung lesen |
ergebnis = SysIni(<inidatei>, <anwendung>, <schlüssel> ) |
gibt entweder den wert zum schlüssel in der anwendung zurück oder "error:" falls die Funktion nicht erfolgreich war |
| einen schlüssel aus einer anwendung löschen (zusammen mit einem evtl. zugewiesenen wert |
ergebnis = SysIni(<inidatei>, <anwendung>, <schlüssel>, "DELETE:") |
ergebnis ist eine Zeichenkette, die entweder leer ist, wenn der Aufruf erfolgreich war oder "error:" wenn ein Fehler auftrat. |
| eine anwendung löschen (zusammen mit allen enthaltenen schlüsseln und den jeweiligen werten) |
ergebnis = SysIni(<inidatei>, <anwendung>, "DELETE:" ) |
ergebnis ist eine Zeichenkette, die entweder leer ist, wenn der Aufruf erfolgreich war oder "error:" wenn ein Fehler auftrat. |
| alle schlüssel einer anwendung ermitteln |
ergebnis = SysIni(<inidatei>, <anwendung>, 'ALL:', <stammvar>) |
gibt die Namen aller schlüssel einer anwendung in einer Stammvariablen zurück. Eintrag .0 der Stammvariable enthält (wie immer) die Anzahl der Einträge, während die Namen der schlüssel in den weiteren Einträgen folgen. |
| die Namen aller anwendungen einer INI-Datei ermitteln |
ergebnis = SysIni(<inidatei>, 'ALL:', <stammvar>) |
gibt die Namen aller anwendungen in einer Stammvariablen zurück. Eintrag .0 der Stammvariable enthält (wie immer) die Anzahl der Einträge, während die Namen der anwendungen in den weiteren Einträgen folgen. |
Damit Sie auch hierfür ein Beispiel vorliegen haben, um dem ganzen besser folgen zu können, habe ich versucht, ein kleines Test- und Spielprogramm zu erstellen. Sie können das folgende Skript in ein leeres Editorfenster kopieren (beispielsweise mit E.EXE), speichern und dann ausführen:
/* SysIni Beispielprogramm */ call rxfuncadd "sysini", "rexxutil", "sysini" meineini = "C:\test.ini" if SysIni(meineini, "anw1", "schl1") = "ERROR:" then call IniAnlegen say "Alle Anwendungen der INI ausgeben:" call SysIni meineini, 'ALL:', 'apps' do i = 1 to apps.0 say apps.i end say "weiter mit enter..." pull line say "Alle schlüssel der anwendung 'anw1' ausgeben:" call SysIni meineini, 'anw1', 'ALL:', 'apps' do i = 1 to apps.0 say apps.i end say "weiter mit enter..." pull line say "Zeige wert für 'schl2':" iniwert = SysIni(meineini, 'anw1', 'schl2') say "wert is:" iniwert say "wird jetzt geändert - weiter mit enter..." pull line call SysIni meineini, 'anw1', 'schl2', 'neuerwert' iniwert = SysIni(meineini, 'anw1', 'schl2') say "neuer wert ist:" iniwert say "weiter mit enter..." pull line say "Lösche schlüssel 'schl2' aus anwendung 'anw1':" call SysIni meineini, 'anw1', 'schl2', 'DELETE:' say "fertig - weiter mit enter..." pull line say "Nochmals alle schlüssel der anwendung 'anw1' anzeigen:" call SysIni meineini, 'anw1', 'ALL:', 'apps' do i = 1 to apps.0 say apps.i end say "weiter mit enter... - programm wird beendet" pull line exit IniAnlegen: call SysIni meineini, "anw1", "schl1", "wert1-1" call SysIni meineini, "anw1", "schl2", "wert1-2" call SysIni meineini, "anw1", "schl3", "wert1-3" call SysIni meineini, "anw2", "schl1", "wert2-1" call SysIni meineini, "anw2", "schl2", "wert2-2" call SysIni meineini, "anw3", "schl1", "wert3-1" return /* -- Ende Beispielprogramm -- */
das Programm prüft zunächst, ob die INI-Datei existiert, indem der Wert für anw1/schl1 ermittelt
wird. Wenn dies fehlschlägt, ist die datei (wahrscheinlich) nicht vorhanden und es wird die Unterroutine
IniAnlegen aufgerufen. Diese legt ein paar Einträge an und kehrt dann zur Hauptroutine
zurück. Dann werden alle anwendungen angezeigt, danach alle schlüssel von anw1. Danach
wird der Wert für den Schlüssel "schl2" in "anw1" geändert und der neue
Wert wieder ermittelt und ausgegeben. Zu guter letzt wird der schlüssel gelöscht und danach
alle (noch) vorhandenen schlüssel der anwendung anw1 ausgegeben. Viel Spaß beim
Herumexperimentieren
Im nächsten Teil kehren wir wieder zurück zu DrDialog! Wir schauen uns an, wie man mit mehreren Dialogfenstern umgeht, besprechen die Fallstricke und Vor- und Nachteile. Damit sollten Sie ein gewisses Maß an Sicherheit im Umgang mit mehreren Dialogfenstern entwickeln. Danach werfen wir einen Blick auf Chris Wohlgemuths Sammlung von Erweiterungen für DrDialog: Eine Fortschrittsanzeige, Tooltip-Fenster, ein Steuerelement für alle von OS/2 (über MMPM/2) unterstützten Grafikformate und weitere Funktionen, um die Hierarchie von mehreren Dialogen zu kontrollieren. Viele Grüße - und bleiben Sie am Ball!
Artikelverzeichnis
editor@os2voice.org
< Vorherige Seite | Inhaltsverzeichnis | Nächste Seite >
VOICE-Homepage: http://de.os2voice.org