




 Artikel
Artikel

Aktives GUI-Element
Statisches GUI-Element
Quelltext
WPS-Objekt
Datei/Pfad
Befehlszeile
Inhalt Eingabefeld
[Tastenkombination]
OS/2 und multilinguale Zeichensätze
Teil 1
Es wird immer wichtiger mit Texten aus verschiedenen Sprachen umgehen zu können: in Anwendungen, in Dokumenten, auf Webseiten und insbesondere in e-Mail-Nachrichten. Dieser Artikel ist der erste in einer Serie, die einige der Schwierigkeiten bespricht, die auftreten, wenn man es mit internationalen Texten unter OS/2 zu tun hat. Diese erste Fortsetzungsausgabe dreht sich um Textanzeigen mit verschiedenen Ein-Byte-Zeichenumsetzungstabellen. In der heutigen immer weiter vernetzten Welt trifft man immer häufiger auf Texte, der nicht nur in einer anderen Sprache verfaßt wurden, sondern ein anderes Alphabet und andere Zeichensätze verwenden. Solche Text findet man in einer e-Mail- oder Newsgruppen-Nachricht, einem Dokument oder einer Benutzerschnittstelle; und wenn man es gefunden hat, stellt man fest, daß es wie Kauderwelsch erscheint (wie verschwommene Zeilen). Wie also wird der Text so angezeigt, wie man es sich wünscht?
Wie die meiste Software ist auch OS/2 "localised", also in verschiedenen sprachspezifischen Versionen vertrieben worden. Jedoch kann jede Sprachversion von OS/2 nahezu jeden Text in verschiedenen Zeichensätzen anzeigen, wenn man nur weiß, wie es geht.
Die richtige Darstellung des Textes auf dem Bildschirm (und beim Ausdruck) hängt von 2 Hauptfaktoren ab:
- die aktuelle Zeichenumsetzungstabelle
- die aktuelle Schriftart
Wenn Zeichen aus einer anderen Sprache nicht richtig angezeigt werden, liegt es immer daran, daß es entweder mit einem oder beiden nicht zusammenpaßt. Glücklicherweise kann man das Problem mit einem bißchen Know-how lösen.
Wenn man OS/2 installiert, wählt man die aktuelle Locale aus; dies legt unter anderem die standardmäßige Systemzeichenumsetzungstabelle und damit den bevorzugten Zeichensatz fest.
Zeichenumsetzungstabellen
Zur Erinnerung: Im wesentlichen sind Computer nichts anderes als Rechenknechte. Jedes Datum, sei es Text, Bilder, Programmcode oder sonst irgendwas anderes, wird intern als Abfolge von 8-Bit-Binärzahlen, sogenannten Bytes, dargestellt.
Eine Zeichenumsetzungstabelle ist nichts weiter als eine Entschlüsselungstabelle, um die Bytes in menschenverständliche Zeichen zu übersetzen. Der Computer verwendet jene Zeichenumsetzungstabelle, die gerade aktiv ist, um festzustellen, welches Zeichen ein gegebener Byte-Wert darstellt.
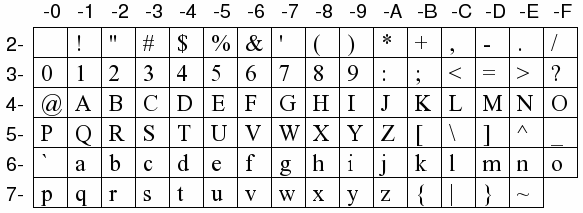
Abbildung 1: Lesbare ASCII-Zeichen, angeordnet nach Byte-Wert
Die meisten Zeichenumsetzungungstabellen basieren auf dem Umsetzungsstandard namens ASCII, der ein Schema verwendet, in welchem ein einzelnes Zeichen durch einen 1-Byte-Wert wiedergegeben wird. Ein Byte kann 256 verschiedene Werte annehmen (0 bis 255) wenn alle 8 Bits verwendet werden, obwohl der ASCII-Standard selbst nur 7 davon verwendet (also Werte von 0 bis 127).
In diesem System sind die Werte 0 bis 31 und 127 für spezielle Anwendungen; Werte von 32 bis 126 (oder 0x20 bis 0x7E in hexadezimaler Schreibweise, wie man Byte-Werte üblicherweise aufschreibt) sind darstellbare Zeichen. Diese Zeichen entsprechen dem modernen lateinischen Alphabet (Klein- wie auch Großbuchstaben), den Ziffern 0 bis 9, den meisten englischen Satzzeichen und 2 weiteren nützlichen Zeichen (siehe Abbildung 1).
Als Beispiel ist hier das englische Wort "Hello" dargestellt in der ASCII-Codierung:
Hexadezimale Byte-Werte: 0x48 0x65 0x6C 0x6C 0x6F Dezimale Byte-Werte: 72 101 108 108 111 Lesbarer Text: H e l l o

Abbildung 2: Zeichensatz 850 (Moderne Version mit Euro-Symbol, z.B. Zeichenumsetzungstabelle 858)
Damals zu DOS-Zeiten war die Standardzeichenumsetzungstabelle in den USA Zeichensatz 437, ein 8-Bit Erweiterung des ASCII. Ein paar Jahre später folgte Zeichensatz 850 (auch "multilingualer" Zeichensatz genannt), der ähnlich dem 437er ist, aber mehr akzentuierte und andere sinnvolle Zeichen enthält. Der Zeichensatz 850 (eine vor kurzem überarbeitete Version enthält das Euro-Währungssymbol) ist wohl nach wie vor der am häufigsten unter OS/2 eingesetzte Zeichensatz.
Mit dem Zeichensatz 850 lassen sich Englisch, Französisch, Deutsch, Italienisch und die meisten anderen westeuropäischen und skandinavischen Sprachen darstellen. Mit jedoch darin nur 256 verfügbaren Werten sind andere Zeichensätze (wie Russisch, Griechisch oder Hebräisch) außerhalb der abdeckbaren Grenzen. Also sind zusätzliche Zeichensätze notwendig - Zeichensatz 869 zum Beispiel wird für Griechisch und Zeichensatz 862 für Hebräisch verwendet.
Alle diese Zeichensätze verwenden die Standard-ASCII-Entschlüsselung für Werte zwischen 0x20 und 0x7E. Sie unterscheiden sich in dem Werten außerhalb dieses Bereichs (0x00 bis 0x19 und 0x7F bis 0xFF). Also sollte jeder Text, der nur die einfachen ASCII-Zeichen (das lateinische Alphabet, die arabischen Ziffern und englische Satzzeichen) verwendet, richtig angezeigt werden.
Das Problem tritt dann auf, wenn man einen Text angezeigt bekommt, der einen anderen Zeichensatz erfordert als den, den man gerade eingestellt hat, also beispielsweise, wenn russischer Text (Zeichensatz 866) angezeigt werden soll und das System auf Latein-1 (Zeichensatz 850) eingestellt ist.
Tatsächlich kann es sogar bei lateinischem Text kompliziert werden. Dies liegt teilweise daran, daß verschiedene Gruppen verschiedene konkurrierende Standards für lateinischen Text außerhalb des einfachen ASCII-Bereichs festgelegt haben.
Latein-1 (oder Lateinisches Alphabet Nr. 1) ist ein ISO-Standard, der einen Satz von 191 Zeichen definiert, wie sie in den meisten lateinisch basierten westeuropäischen Sprachen verwendet werden. Zeichensatz 850 setzt den Latein-1-Zeichensatz um und fügt noch einige Sonderzeichen hinzu. Unglücklicherweise bringt ISO eine eigene Zeichenumsetzungstabelle heraus, technisch gesprochen Zeichensatz 819, aber meist nur bekannt als "ISO-8859-1" ( oder "ISO-Latein-1"), die die nicht ASCII-Latein-1-Zeichen gänzlich anders anordnet.
Microsoft entschloß sich ISO-8859-1 für das Windowssystem zu nehmen; so ungefähr. Windows verwendet einen erweiterten ISO-8859-1-Zeichensatz, Zeichensatz 1252 genannt für Latein-1-Texte. Viele Webseiten und e-Mail-Nachrichten behaupten eine ISO-8859-1-Umsetzung zu haben, obwohl sie tatsächlich den umfassenderen Zeichensatz 1252 haben; infolgedessen behandeln die meisten Anwendungen diese zwei Zeichensätze wie einen.
Die verbreitete Verwendung verschiedener Zeichensätze erklärt, warum man manche Nachrichten, die man von anderen Leuten bekommt (insbesondere Windows-Anwendern), manchmal komische Symbole enthalten, weil die andere Person ein Zeichen außerhalb des einfachen ASCII-Bereichs verwendet. Glücklicherweise hält OS/2 alternative Zeichensätze bereit, die diese verschiedenen Entschlüsselungen unterstützen. Einer der wertvollsten ist dabei Zeichensatz 1004, eine Erweiterung des Zeichensatz 1252 (und daher unterstützt er beide, 1252 und ISO-8859-1).
| Name | Zeichensatznummer | Zeichen | Codierungstabelle |
|---|---|---|---|
| Latein-1 Multilingual | 850 | Lesbarer ASCII Satz plus 159 zusätzliche Zeichen | (Image) |
| ISO-8859-1 | 819 | Lesbarer ASCII Satz plus 95 zusätzliche Zeichen | (Image) |
| Windows Latein-1 | 1252 | ISO-8859-1 plus 27 zusätzliche Zeichen | (Image) |
| Windows Erweitertes Latein | 1004 | Windows Latein-1 plus 7 zusätzliche Zeichen | (Image) |
ISO hat noch andere Zeichensätze definiert; andere Latein-basierte Zeichensätze enthalten Latein-2 (enthält Zeichenvarianten aus den slawischen Sprachen), Latein-4 (für baltische Sprachen), Latein-5 (für Türkisch) und Latein-9 (ein neuerer Ersatz für Latein-1). Roman Czyborra hat zu vielen von diesen Zeichensätzen eine exzellente Beschreibung.
Einstellen des Zeichensatzes
Einige moderne Anwendungen (hervorzuheben ist de Familie der Mozillaprodukte) sind so hochentwickelt, daß sie mannigfaltige Zeichensätze ohne viel Aufheben umsetzen, obwohl man ihnen in manchen Fällen ausdrücklich die Sprache mitteilen muß. In den meisten Fällen jedoch haben wir weniger Glück.
Das OS/2-System selbst holt sich die Zeichensatzeinstellung aus der CONFIG.SYS, und zwar über die Anweisung:
CODEPAGE=xxx[,yyy]
mit xxx für den primären Zeichensatz und yyy ist für den zweiten Zeichensatz.
Der primäre Zeichensatz ist derjenige, der von OS/2 (und allen laufenden Anwendungen) als Standard verwendet wird. Der zweite Zeichensatz ist eine wahlfreie Alternative, die auf einer "je Prozeß"-Basis aktiviert werden kann. Man kann in einer Fenster- oder Gesamtbildschirm-Befehlszeilensitzung auf den zweiten Zeichensatz umschalten, mittels des CHCP-Befehls:
CHCP 437
Und auf den ursprünglichen Zeichensatz zurückschalten geht auf dem gleichen Wege.
Diese Änderung wirkt sich nur auf die aktuelle Sitzung und alle Programme, die aus dieser Sitzung heraus
gestartet wurden. Das OS/2-Installationsprogramm setzt normalerweise den ersten und zweiten Zeichensatz, je nach
dem, was für Ihre Region als angemessen betrachtet wird. Für die meisten Englisch, Französisch,
Deutsch, Flämisch, Spanisch, Portugiesisch und Italienisch sprechenden Länder ist dies typischerweise
850,437 (außer in den USA, wo 437,850 eher üblich ist).
Die möglichen Zeichensätze, die über die CODEPAGE-Anweisung eingestellt werden
können, werden über den Gerätetreiber COUNTRY.SYS festgelegt. Die
wichtigsten sind unter anderem:
437 (DOS Erweiterter ASCII / United States)
850 (Latein-1 / Multilingual)
852 (Latein-2 / Slawisch)
855 (Kyrillisch)
857 (Latein-5 / Türkisch)
862 (Hebräisch)
863 (Kanadisch / Französisch erweiterter ASCII)
864 (Arabisch)
866 (Kyrillisch / Ru▀land)
869 (Griechisch)
874 (Thai)
921 (Baltisch)
922 (Baltisch / Estland)
932 (Japanisch SJIS-1990)
949 (Koreanisch KS-Code)
950 (Traditionelles Chinesisch / Taiwan Big-5)
1004 (Windows erweitertes Latein)
1386 (Vereinfachtes Chinesisch / China GBK)
Anwendungen und Zeichensätze
OS/2-Anwendungen können tatsächlich zwei Zeichensätze benutzen. Der Hauptzeichensatz ist der Prozeßzeichensatz, der von jedem laufenden Programm vom Elternprozeß geerbt wird. Da OS/2 selbst den primären Zeichensatz verwendet, werden die meisten Programme dies auch erben; jedoch kann jedes Programm seinen Prozeßzeichensatz zwischen dem ersten und zweiten Zeichensatz auswählen, und welcher auch immer ausgewählt wurde, er wird an alle Kinderprozesse weiter vererbt. Man beachte, daß der Zeichensatz nur einer von den beiden Festgelegten sein kann (in der CONFIG.SYS).
Das ist der Umfang der Zeichensatzunterstützung für Textmodus-Programme. Auf der anderen Seite können grafische Presentation-Manager-Applikationen auch den Nachrichtenwarteschlangenzeichensatz verwenden - üblicherweise als PM-Zeichensatz bezeichnet. Der PM-Zeichensatz legt fest, wie Zeichen in GUI-Fenstern dargestellt werden.
Normalerweise ist der PM-Zeichensatz der gleiche wie auch der Prozeßzeichensatz. Jedoch ist es möglich, den Zeichensatz bei Bedarf zu ändern, und noch bedeutender, der PM-Zeichensatz ist nicht auf die zwei Zeichensätze begrenzt, die in der CONFIG.SYS festgelegt sind, was bedeutet, daß jedes grafische OS/2-Programm jedes Zeichen in nahezu jedem Zeichensatz darstellen kann. (Dieser PM-Zeichensatz findet jedoch keine Anwendung auf gedruckte Ausgaben.)
Wie also wechselt man den PM-Zeichensatz? Nun, im günstigsten Fall gibt es Programme, die diese Möglichkeit selber anbieten. Eines dieser Beispiele ist Version 1.9.2 der AE-Texteditors von Aaron Lawrence, der ein Menü zur Auswahl der Zeichensätze enthält.
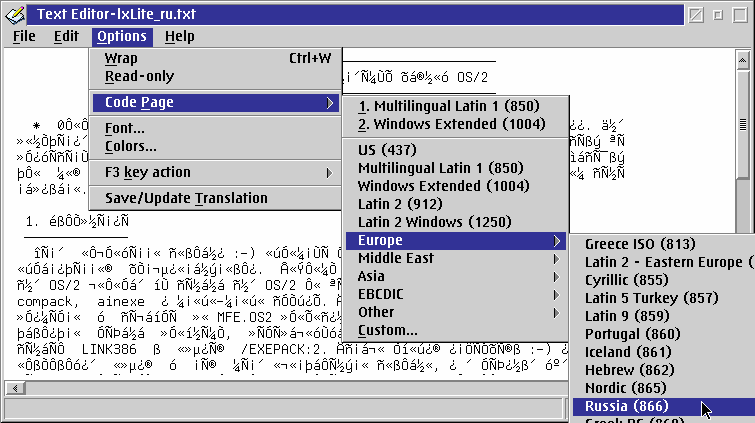
In Abbildung 3a wurde eine russische Textdatei im AE-Editor geöffnet. (Wie man erkennen kann, es ist mit dem voreingestellten Zeichensatz 850 nicht lesbar.) Aus dem Menü kann man nun den Zeichensatz auf Russisch 866 ändern.
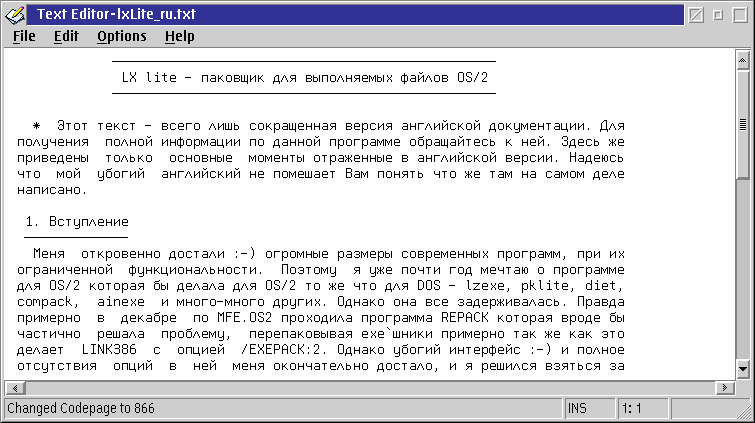
Abbildung 3b zeigt die Datei, nachdem der Zeichensatz geändert wurde. Der russische Text wird nun richtig angezeigt.
Die Anzahl Programme, die diese Funktion unterstützen, ist jedoch eher gering. Sogar in den Versionen nach 1.9.2 ist dies im AE bedauerlicherweise nicht mehr dabei (hauptsächlich, so sieht es aus, weil Aaron mit den Einschränkungen unzufrieden war - wie zum Beispiel die fehlende Druckunterstützung, wie schon erwähnt).
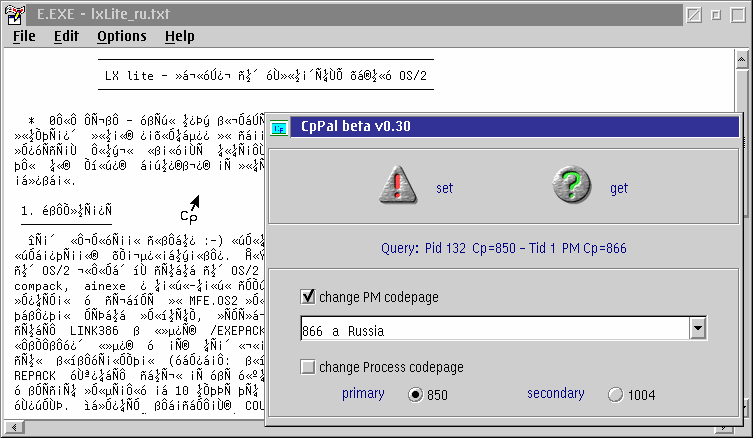
Glücklicherweise kann der PM-Zeichensatz auch von außen durch den Anwender gesetzt werden. Rich Walsh (er sollte den meisten als Autor von DragText gut bekannt sein) hat ein kleines handliches Programm namens CPPal geschrieben. Dies funktioniert in etwa wie eine Zeichensatzpalette, die es erlaubt, den PM-Zeichensatz eines Programmes durch Ziehen und Übergeben zu ändern.
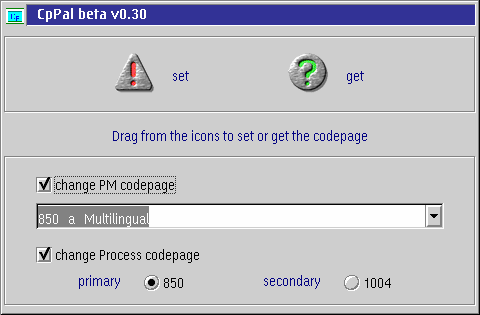
Abbildung 4: CPPal
CPPal enthält eine Auswahlliste von möglichen PM-Zeichensätzen. Moderne OS/2-Systeme haben davon eine beachtliche Anzahl, und einige davon sind sehr merkwürdig (Zeichensatz 383 zum Beispiel ist eine Umsetzung für belgische Verlagssysteme auf IBM-Mainframes).
Hat man den gewünschten PM-Zeichensatz von der Liste ausgewählt, setzt man einfach den Mauszeiger auf das set-Icon und zieht und übergibt ihn in die Anwendung, deren Zeichensatz man ändern möchte.
Man kann auch den PM-Zeichensatz der gerade laufenden Anwendung auf die gleiche Weise mit dem get-Icon abfragen. Der Anzeigetext in der Mitte des CPPal-Fensters ändert sich und zeigt den aktuell verwendeten Zeichensatz an.
In Abbildung 5a wurde die gleiche russische Textdatei mit dem OS/2-Systemeditor geöffnet, der keine eingebaute Möglichkeit zur Änderung des Zeichensatzes hat. Also startet man CPPal und wählt den Zeichensatz 866 (Russisch) aus der Liste. Dann zieht man den Mauszeiger vom set-Icon auf das Systemeditorfenster( das Aussehen des Mauszeigers ändert sich, wie dargestellt, wenn er auf ein zulässiges Ziel geführt wird).
Abbildung 5b zeigt die Datei, nachdem der Zeichensatz geändert wurde.
{kind=link}
{kind=link}
{kind=link}
Es wird relativ häufig notwendig sein, die Schriftart im Zielfenster zu ändern, bevor der Zeichensatzeffekt sichtbar wird. CPPal versucht dies zwar automatisch umzusetzen, aber mit mäßigem Erfolg (tatsächlich wird die Schriftart im Systemeditor immer auf System Proportional zurückgesetzt, wenn CPPal angewendet wurde, obwohl das in Abbildung 5 nicht zu sehen ist).
Eigentlich überflüssig zu erwähnen, daß diese Technik auch funktioniert, wenn verschiedene lateinische Zeichensätze angezeigt werden sollen, gleichsam der Anzeige von Texten mit gänzlich anderen Zeichensätzen. Wenn Sie zum Beispiel eine Datei oder eine e-Mail-Nachricht erhalten, die auf einem Windows-Latein-1-Zeichensatz (1252) basiert, dann wechseln Sie auf Zeichensatz 1252 oder 1004 um sicherzustellen, das alle Zeichen richtig dargestellt werden.
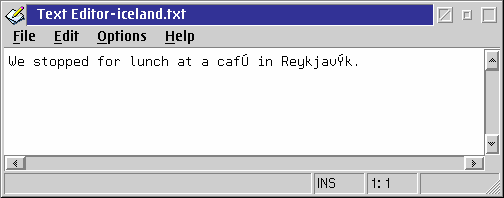
Abbildung 6a: Text von einem Windowssystem - mit Zeichensatz 850 angezeigt
In Abbildung 6a sieht man ein Textfragment (mit zwei Sonderzeichen) das auf eine Windowssystem mit Zeichensatz 1252 geschrieben wurde. Das eingesetzte OS/2-System dagegen ist für Zeichensatz 850 ausgelegt.
In diesem Beispiel benutzen wir den AE-Version 1.9.2, so daß wir die Zeichensatzmenüoption anwenden können, um einen brauchbaren Zeichensatz auszuwählen (CPPal hätte natürlich auch funktioniert). Wir könnten Zeichensatz 1252 nehmen; jedoch ist Zeichensatz 1004 mit Zeichensatz 1252 voll verträglich und ist im AE-Menü leichter zu finden, so daß wir ihn für dieses Beispiel stattdessen verwendet haben.
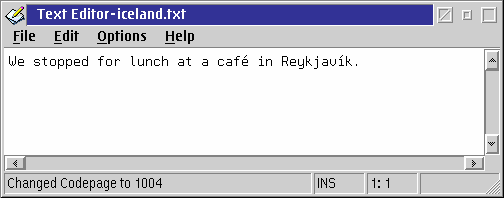
Abbildung 6b: Der gleiche Text, nun unter Zeichenumsetzungstabelle 1004 angezeigt
Abbildung 6b zeigt nun den Text nach Umschalten auf den Zeichensatz 1004. Die Buchstaben é und í werden nun richtig dargestellt.
Stattdessen kann man auch, wenn der Zeichensatz 1004 als zweiter Zeichensatz in der CONFIG.SYS definiert ist, den Prozeßzeichensatz ändern; dies hat den Vorteil, daß man die Datei selbst in einer Befehlszeilensitzung richtig anzeigen lassen kann.
[D:\]chcp 1004
[D:\]type iceland.txt
We stopped for lunch at a café in Reykjavík.
Schriftarten
Das Ändern des Zeichensatzes ist meist nicht ausreichend um die Zeichen angezeigt zu bekommen, wie man es braucht. Die aktuelle Schriftart muß auch die den Zeichen entsprechenden Bildzeichen (Glyphen) vorhalten, da sie sonst nicht richtig angezeigt werden können.
Ein Zeichen, das in der aktuellen Schriftart nicht vorhanden ist, wird üblicherweise durch ein Ersatzzeichen dargestellt, das durch die Schriftart selber festgelegt ist (die standardmäßigen OS/2-Schriftarten verwenden meist ein kleines unausgefülltes Rechteck "☐" Unicode-Schriftarten verwenden meist ein spezielles Zeichen, wie etwas das "�").
Für die meisten europäischen Sprachen ist dies normalerweise kein Problem, da die meisten Standard-OS/2-Schriftarten eine ausreichende Auswahl an lateinischen, griechischen, kyrillischen, hebräischen, arabischen, thailändischen, mathematischen, blockgrafischen und verschiedenen anderen Zeichen bieten. Die Win-OS/2-TrueType-Schriftarten, die man meist auf OS/2-Systemen findet (wie auch einige ihrer moderneren Pendanten), sind jedoch meist sehr viel begrenzter in ihrem Umfang, wie dies auch bei vielen Schriften aus anderen externen Quellen der Fall sein kann.
Wenn man viel mit Dokumenten und Webseiten zu tun hat (wenn also die in OS/2 eingebauten Bitmap-Schriften nicht genügen), sollte man sich nach Unicode-Schriftarten umschauen, die dazu entworfen wurden, um internationale Texte darstellen zu können. Diese haben meist "Unicode" irgendwo im Namen, obwohl die, die von IBM geliefert werden, meist auf "WT" (steht für "WeltTyp") lauten.
Auch eine Unicodeschriftart ist nicht notwendigerweise eine Garantie für die Unterstützung aller möglichen Zeichen, aber es ist letztlich eine wesentlich größere Chance, daß Zeichen außerhalb des Latein-1-Zeichensatzes unterstützt werden. Der einzige Weg dies herauszufinden ist, die Dokumentation zu der Schriftart zu studieren - oder es einfach auszuprobieren und selbst anzusehen.
Nutzt man bei den letzten OS/2-Versionen (Warp Server for e-business oder neuer) die "Unicodeschriftarten"-Möglichkeit bei der Installation, so erhält man einige hochwertige TrueType-Unicodeschriftarten:
- Monotype Sans Duospace WT J
- Eine nichtproportionale Sans-Serif-Schriftart mit Unterstützung der meisten europäischen Sprachen, der asiatischen Sprachen und der Sprachen des mittleren Ostens.
- Monotype Sans WT
- Eine proportionale Sans-Serif-Schriftart mit Unterstützung für viele europäische Sprachen.
- Times New Roman WT J
- Eine proportionale Serifen-Schriftart mit Unterstützung der meisten europäischen Sprachen, der asiatischen Sprachen und der Sprachen des mittleren Ostens. Oft auch "Times New Roman MT 30" genannt, zur Erhaltung der Rückwärtskompatibilität.
Dann gibt es noch zahlreiche andere Unicodeschriftarten, einige davon sind hiernach aufgelistet ("Bitstream Cyberbit", die sowohl frei erhältlich als auch ziemlich umfassend ist, könnte insbesondere für ältere OS/2-Versionen interessant sein).
| Schriftname | Beschreibung | Verfügbarkeit |
|---|---|---|
| Arial Unicode MS | Proportionale Sans-Serif-Schriftart mit Unterstützung der meisten europäischen Sprachen, der asiatischen Sprachen und der Sprachen des mittleren Ostens. | ARIALUNI.TTF kann von einem Windows 2000- oder XP-System kopiert werden, soweit man eine Lizenz hat. |
| Bitstream Cyberbit | Proportionale Serifen-Schriftart mit Unterstützung der meisten europäischen Sprachen, der asiatischen Sprachen und der Sprachen des mittleren Ostens. | Cyberbit.ZIP kann man von hier herunterladen. Es ist kostenlos, darf aber nicht weitergegeben werden. |
| Code2000 | Proportionale Serifen-Schriftart mit sehr breiter Unterstützung verschiedener Sprachen und Skripte aus aller Welt. | Shareware und erhältlich von seiner Webseite. |
| Lucida Sans Unicode | Proportionale Sans-Serif-Schriftart mit Unterstützung der meisten europäischen Sprachen und Hebräisch. | Bestandteil in Microsofts "core web fonts" Packet, das man an vielen Stellen findet, unter anderem bei Hobbes. |
| Times New Roman MT 30 | Proportionale Serifen-Schriftart mit Unterstützung der meisten europäischen Sprachen, der asiatischen Sprachen und der Sprachen des mittleren Ostens. Dies ist eine ältere Version der "Times New Roman WT J". | Bestandteil von vielen Distributionen der IBM Java-1.1.8-Runtime-Umgebung. |
Abschlußbemerkung
Die Informationen in diesem Artikel beziehen sich in erster Linie auf die traditionellen "ein Byte"-Zeichenumsetzungen, indem ein Byte ein Zeichen repräsentiert. Wie Sie sicher bemerkt haben, habe ich es vermieden, die ostasiatischen Sprachen wie Chinesisch, Japanisch oder Koreanisch zu besprechen, die eine etwas andere Entschlüsselung benötigen. Die Prinzipien, die hier besprochen wurden, lassen sich auch auf diese anderen Sprachen anwenden, jedoch sind da noch einige Besonderheiten zu beachten.
Auch werden Sie festgestellt haben, daß das gesamte System der Zeichensätze einen ziemlich gravierenden Nachteil hat: Was ist, wenn Sie eine Text erhalten, der verschiedene Zeichensätze enthält? Zum Beispiel: Wie wollen Sie ein Dokument behandeln, das sowohl hebräischen als auch russischen Text enthält?
Wenn alles gut geht, werden beide Themen in weiteren Artikeln behandelt.