




 Feature articles
Feature articles

Active GUI element
Static GUI element
Code
WPS object
File/Path
Command line
Entry-field content
[Key combination]
OS/2 and Multilingual Character Sets
Part 1
It is becoming increasingly important to deal with text from different languages: in applications, in documents, on web sites, and even in e-mail messages. This article is the first in a series that discusses some of the issues involved in handling international text under OS/2. This first installment focuses on viewing text in various single-byte codepages.
In today's increasingly connected world, it is becoming common to encounter text written not just in different languages, but in different alphabets and other character sets. You may find such text in an e-mail or newsgroup message, document, or user interface—and if you have, you have probably found that it displays as gibberish (resembling line noise). So how do you get such text to display as intended?
Like most software, OS/2 is localized—distributed in language-specific versions. However, any language version of OS/2 is capable of displaying text in different character sets, as long as you know the necessary tricks.
The correct display of text on your screen (and when printed) depends on two main factors:
- The active codepage.
- The current font.
If characters in another language fail to display correctly, it is generally because it is incompatible with either or both of these. Fortunately, you can usually correct this problem with a little know-how.
When you install OS/2, you select the current locale; this, among other things, determines the default system codepage and hence the default character set.
Codepages
Remember that, fundamentally, computers are nothing more than number-crunching machines. All data, whether text, images, program code, or anything else, are represented internally as sequences of 8-bit binary numbers called bytes.
A codepage is simply an encoding table that translates bytes into human-readable characters. The computer uses whichever codepage is currently active to determine what character a given byte value represents.
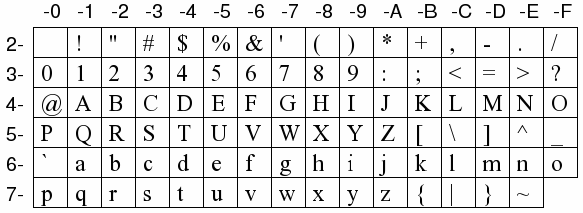
Most codepages are based on an encoding standard called ASCII which uses a scheme whereby a single character is represented by a single byte. A byte can hold 256 different values (0 to 255) when all eight bits are used, although the ASCII standard itself only uses seven of them (defining values 0 to 127).
Under this system, values 0 - 31 and 127 are reserved for special use; values 32 - 126 (or 0x20 - 0x7E in hexadecimal notation, which is how byte values are generally written) are displayable characters. These characters correspond to the modern Latin alphabet (in both lower and upper case forms), the numerals 0 through 9, the most common English punctuation marks, and a couple of other useful symbols (see Figure 1).
The numeric headings in Figure 1 (and the other code charts in this article) indicate each character's byte value. Take the number on the left first, combine it with the number on the top to form the hexadecimal byte code for any given character. So, in Figure 1, “V” is hexadecimal 56, normally written as 0x56; the tilde “~” is 0x7E. (0x20 is the space character.)
As an example, here is the English word “Hello” as represented by ASCII encoding:
Hexadecimal byte values: 0x48 0x65 0x6C 0x6C 0x6F
Decimal byte values: 72 101 108 108 111
Human-readable text: H e l l o

Figure 2. Codepage 850 (modern version with Euro symbol, i.e., codepage 858)
Back in the days of DOS, the standard codepage used in the United States was codepage 437, an eight-bit superset of ASCII. It was followed a few years later by codepage 850 (also called the “multilingual” codepage), which is similar to 437 but contains a wider range of accented forms and other useful characters. Codepage 850 (a slightly revised version which includes the Euro currency symbol) probably remains the most commonly-used codepage under OS/2 today.
Codepage 850 is capable of adequately representing English, French, German, Italian, and most other Western European and Scandinavian languages. However, with only 256 possible values available other character sets (such as Slavic, Russian, Greek, or Hebrew) are beyond its capacity. So additional codepages are necessary—codepage 869, for example, is for Greek, and codepage 862 is for Hebrew.
All of these codepages use the standard ASCII character encoding for values between 0x20 and 0x7E. Where they differ is in the values outside this range (0x00 to 0x19, and 0x7F to 0xFF). So any text that uses only basic ASCII characters (the Latin alphabet, standard Arabic numerals, and English punctuation marks) should always display correctly under any one of them.
The problem arises when you need to display text that requires a different codepage from the one you are currently using: for instance, displaying Russian text (codepage 866) when your system is configured for Latin-1 (codepage 850).
Actually, even for Latin text, the situation can get quite complicated. Part of the problem is that different groups have come up with various competing standards for encoding Latin text outside the basic ASCII range.
Latin-1 (or “Latin Alphabet no. 1”) is an ISO standard that defines a set of 191 characters used in most Latin-based Western European languages. Codepage 850 implements the Latin-1 character set, and adds a number of extra characters. Unfortunately, ISO provides its own codepage—technically codepage 819 but more commonly called “ISO-8859-1” (or “ISO Latin-1”)—which encodes the non-ASCII Latin-1 characters in an entirely different arrangement.
Microsoft elected to adopt ISO-8859-1 for its Windows operating systems… sort of. Windows uses a superset of ISO-8859-1, called codepage 1252, for Latin-1 text. Many web sites and e-mail messages claim to use ISO-8859-1 encoding when they are actually using the more comprehensive codepage 1252; consequently, most applications have taken to treating the two as equivalent.
The widespread use of different codepages explains why messages you receive from other people (especially Windows users) may have the occasional strange symbol in places where the other person used a character outside the basic ASCII range. Fortunately, OS/2 provides alternate codepages which support all of these different encodings. One of the most useful is codepage 1004 which is a superset of codepage 1252 (and therefore supports both it and ISO-8859-1).
| Name | Codepage number | Characters | Code chart |
|---|---|---|---|
| Latin-1 Multilingual | 850 | Displayable ASCII set plus 159 additional characters | Chart |
| ISO-8859-1 | 819 | Displayable ASCII set plus 95 additional characters | Chart |
| Windows Latin-1 | 1252 | ISO-8859-1 plus 27 additional characters | Chart |
| Windows Extended Latin | 1004 | Windows Latin-1 plus 7 additional characters | Chart |
{kind=link}
{kind=link}
{kind=link}
ISO defines a number of other character sets as well. Other Latin-based ones include Latin-2 (which includes character variations used in the Slavic languages), Latin-4 (for Baltic languages), Latin-5 (for Turkish), and Latin-9 (a recent replacement for Latin-1). Roman Czyborra has an excellent description of many of these.
Setting the codepage
Some modern applications (most notably the Mozilla family of products) are sophisticated enough to interpret multiple codepages without much fuss—although in some cases you may need to explicitly tell them what language to use. In most cases, however, we are not so fortunate.
The OS/2 system itself takes its codepage setting from CONFIG.SYS, specifically from the statement
CODEPAGE=xxx[,yyy]
where xxx is the primary codepage, and yyy is the secondary codepage.
The primary codepage is what OS/2 (and all running applications) use by default. The secondary codepage is an optional alternate codepage that can be activated on a per-process basis. You can switch to the secondary codepage within a specific windowed or full-screen command prompt using the CHCP command, such as:
CHCP 437
And you can change back to the primary codepage again in the same way. The change affects only the current session and any program started from that session.
The OS/2 install program normally sets the primary and secondary codepages to
whatever is deemed most appropriate for your locale. For most English-,
French-, German-, Dutch-, Spanish-, Portuguese- and Italian-speaking countries,
this is typically 850,437 (except in the USA where
437,850 seems to be more common).
The possible codepages which may be specified using the CODEPAGE
setting are determined by the device driver
COUNTRY.SYS. The major ones include:
437 (DOS Extended ASCII / United States)
850 (Latin-1 / Multilingual)
852 (Latin-2 / Slavic)
855 (Cyrillic)
857 (Latin-5 / Turkey)
862 (Hebrew)
863 (Canadian French Extended ASCII)
864 (Arabic)
866 (Cyrillic / Russia)
869 (Greek)
874 (Thai)
921 (Baltic)
922 (Baltic / Estonia)
932 (Japanese SJIS-1990)
949 (Korean KS-Code)
950 (Traditional Chinese / Taiwan Big-5)
1004 (Windows Extended Latin)
1386 (Simplified Chinese / China GBK)
Applications and codepages
OS/2 applications can actually make use of two separate codepage settings. The main one is the process codepage, which is inherited by every running program from its parent process. Since OS/2 itself uses the primary codepage, that is what most programs inherit; however, any program can choose to switch its process codepage between the primary and secondary codepages, and whichever one it chooses is inherited in turn by any of its child processes. Note, however, that the process codepage can only be one of those two (as defined in CONFIG.SYS).
This is the extent of the codepage support available to text-mode programs. Graphical Presentation Manager applications, on the other hand, may also make use of a message queue codepage—commonly referred to as the PM codepage. The PM codepage determines how characters are displayed within GUI windows.
Normally, the PM codepage is the same as the process codepage. However, it is possible to change it on demand. More significantly, the PM codepage is not limited to just the two codepages defined in CONFIG.SYS… which means that graphical OS/2 programs can display characters in almost any known character set. The PM codepage does not extend, however, to printed output.
So how do you change the PM codepage? Well, first of all, some programs offer the option themselves. One of the best examples is version 1.9.2 of Aaron Lawrence's text editor AE which provides a menu of codepages to select.
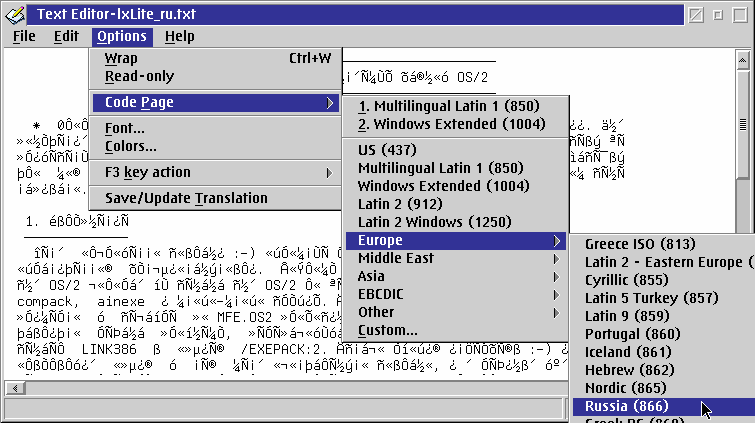
Figure 3-a. Changing the codepage in AE [Larger image]
In Figure 3-a, a Russian-language text file has been opened in the AE text editor. As you can see, it appears unintelligible under the default codepage of 850. From the menubar, we have the option of changing the codepage to Russian (codepage 866).
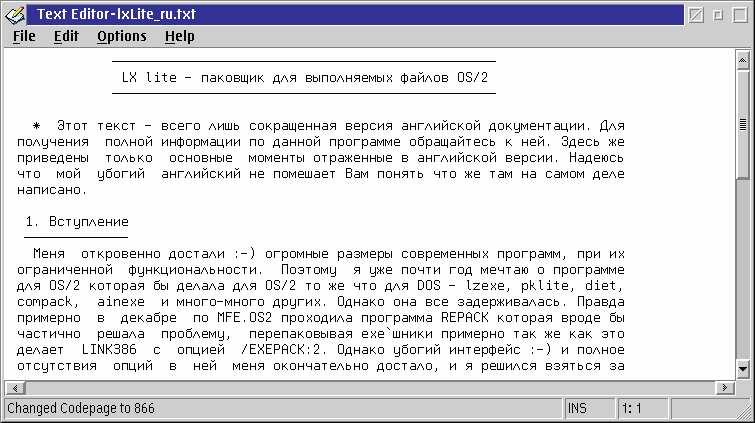
Figure 3-b: After changing the codepage [Larger image]
Figure 3-b shows the file after the codepage has been changed. The Russian text now appears correctly.
The number of programs which actually provide this feature, however, is small. Even AE, sadly, dropped it in versions after 1.9.2 (mainly, it seems, because Aaron was unsatisfied with its limitations—such as the lack of print support mentioned earlier).
Fortunately, the PM codepage can also be set externally by the user. Rich Walsh (who should be well known to many OS/2 users as the author of DragText) has written a handy little program called CPPal. This actually functions as a kind of “codepage palette”, allowing you to change the PM codepage of a program by drag-and-drop.
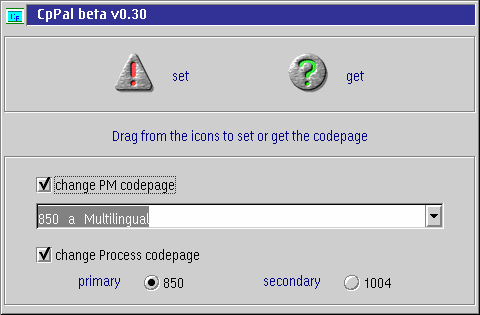
Figure 4: CPPal
CPPal provides a drop-down list of possible PM codepages. Modern OS/2 systems have a large number of these available, some of them quite obscure (codepage 383, for instance, is an IBM mainframe encoding for Belgian publishing symbols).
Once you have selected the PM codepage you want from the list, simply place the mouse over the set icon and then drag and drop it onto the application whose codepage is to be changed.
You can also query an application's current PM codepage by dragging and dropping the get icon in the same way. The message text in the middle of the CPPal window changes to show the current codepage.
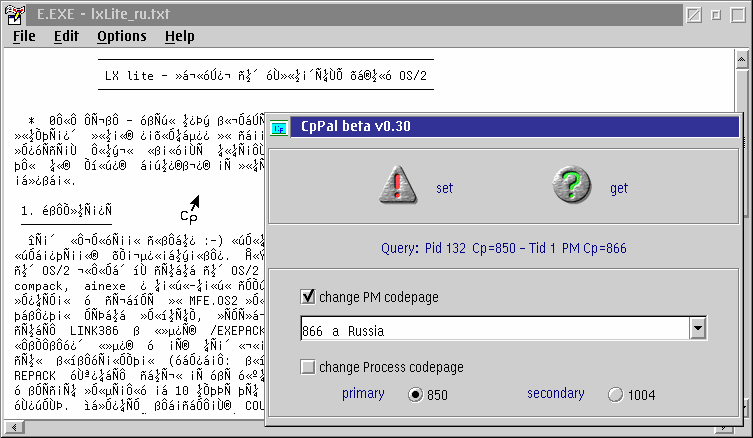
Figure 5-a: Changing the codepage in the System Editor with CPPal [Larger image]
In Figure 5-a, the same Russian-language text file has been opened in the OS/2 System Editor (e.exe) which has no built-in mechanism for changing the codepage. So we open CPPal, and select codepage 866 (Russia) from the list. Then we drag the mouse from the set icon onto the System Editor window (the mouse pointer changes, as shown, when it is over a legal target).
Figure 5-b shows the file after the codepage has changed.
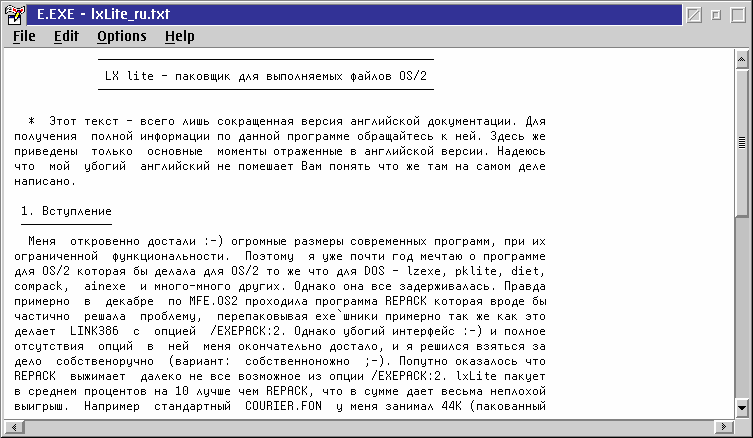
Figure 5-b: After changing the codepage with CPPal [Larger image]
It is often necessary to manually reset the font in the target window before the codepage change takes effect. CPPal attempts to do this automatically but with somewhat limited success. In fact, when using the System Editor, the font usually reverts to System Proportional after using CPPal, although this is not shown in Figure 5-b.
Needless to say, these techniques apply just as much to viewing text in different Latin codepages as they do to text in completely different character sets. For instance, if someone sends you a file or email message that was created under the Windows Latin-1 codepage (1252), you can change your codepage to 1252 or 1004 to make certain that all the characters display correctly.

Figure 6-a: Text from a Windows system as seen under codepage 850
In Figure 6-a, we see a fragment of text (containing two non-ASCII characters) that was written on a Windows system using codepage 1252. The OS/2 system being used, however, is configured for codepage 850.
In this example, we are using AE version 1.9.2, so we can use the codepage menu option to select a more suitable codepage. (Using CPPal would also work, of course.) We could choose codepage 1252; codepage 1004, however, is fully compatible with 1252, and happens to be located more handily in AE's menu, so for this example we use that one instead.

Figure 6-b: The same text, now seen under codepage 1004
Figure 6-b shows the text after switching to codepage 1004. The é and í characters now display properly.
Alternatively, if you have codepage 1004 defined as your secondary codepage in CONFIG.SYS, you can change the process codepage instead; this has the advantage of allowing you to view the file correctly even in a command prompt.
[D:\]chcp 1004
[D:\]type iceland.txt
We stopped for lunch at a café in Reykjavík.
Fonts
Changing the codepage isn't always enough to display the characters you need. The current font also has to actually contain glyphs for those characters, otherwise they are not displayed properly.
A character that does not exist in the current font is typically indicated by a “substitution” character which is defined by the font (the standard OS/2 fonts mostly use an empty rectangular box “☐” [which may also appear as a question mark]; modern Unicode fonts often use a special character like “�”).
For the most common European languages this is rarely a problem since most of the standard OS/2 system fonts include a fairly comprehensive range of Latin, Greek, Cyrillic, Hebrew, Arabic, Thai, mathematical, box-drawing, and miscellaneous publishing characters. The Win-OS/2 TrueType fonts commonly found on OS/2 systems (and even some of their modern equivalents), however, are much more limited in scope, as may be various other fonts from third-party sources.
When dealing with documents and web pages (when OS/2's built-in bitmap fonts may not suffice), you are advised to look for Unicode fonts which are designed to handle international text. These usually have “Unicode” somewhere in the name (although the ones that IBM provides use the name “WT”, for ”WorldType”, instead).
A Unicode font is not necessarily guaranteed to contain support for all possible character sets, but is at least more likely than others to support character ranges outside Latin-1. The only way to find out for certain is to check the font's documentation. . ., or simply try it out and see for yourself.
If you allow the latest versions of OS/2 (Warp Server for e-business or later) to install the “Unicode fonts” option, you end up with several high-quality TrueType Unicode fonts:
- Monotype Sans Duospace WT J
- A monospaced sans-serif font with support for most major European, Middle-Eastern and Asian languages.
- Monotype Sans WT
- A proportional sans-serif font with support for several European languages.
- Times New Roman WT J
- A proportional serif font with support for most major European, Middle-Eastern and Asian languages. Normally also aliased to “Times New Roman MT 30” for backwards compatibility.
There are a number of other popular Unicode fonts available, some of which are listed in the table below. (”Bitstream Cyberbit”, which is both free and relatively comprehensive, may be particularly useful for users of earlier OS/2 versions.)
| Font Name | Description | Availability |
|---|---|---|
| Arial Unicode MS | Proportional sans-serif font with support for most major European, Middle-Eastern and Asian languages. | ARIALUNI.TTF can be copied from a Windows 2000 or XP system, so long as you have a license for it. |
| Bitstream Cyberbit | Proportional serif font with support for most major European, Middle-Eastern and Asian languages. | Cyberbit.ZIP can be downloaded from here. It is free for use but may not be redistributed. |
| Code2000 | Proportional serif font with support for a very large range of languages and scripts from all over the world. | Shareware available from its website. |
| Lucida Sans Unicode | Proportional sans-serif font with support for most major European languages, as well as Hebrew. | Included in Microsoft's “core web fonts” package, available from multiple locations including Hobbes. |
| Times New Roman MT 30 | Proportional serif font with support for most major European, Middle-Eastern and Asian languages. This is an older version of “Times New Roman WT J”. | Included with some distributions of the IBM Java 1.1.8 runtime environment. |
Closing Remarks
The information in this article applies primarily to traditional “single byte” character encoding, where one byte represents one character. As you may have noticed, I have avoided discussing East Asian languages like Chinese, Japanese, and Korean, which require a slightly different type of encoding. The principles discussed here do apply to these other languages, but there are some additional caveats involved.
You may also have noticed that the entire system of codepages has a fairly major weakness: What if you want to display text from many different character sets at the same time? For instance, how do you deal with a document that contains both Hebrew and Russian text?
If all goes well, both of these topics will be addressed in future articles.