




 Feature articles
Feature articles

Active GUI element
Static GUI element
Code
WPS object
File/Path
Command line
Entry-field content
[Key combination]
OS/2 and Multilingual Character Sets
Part 3
Welcome to the third article in a series that discusses some of the issues involved in dealing with international text under OS/2. This installment deals with text on the Internet, and takes a look at how certain applications handle it.
So, you're looking at an email message or web page that contains funny characters that you know aren't right, and you'd like to see them as their author intended. Or perhaps some of your email correspondants are complaining that your messages are full of messed-up characters. Or maybe you've just found yourself wondering exactly what a ‘charset’ is, and how it works.
This article takes a look at these and other issues.
Charsets
Most Internet documents, like e-mail messages, newsgroup posts, and web pages, make use of something called a charset identifier. This is essentially a parameter that tells your mail client, newsreader, or web browser what character encoding (or charset) the file is using.
In an HTML document, the charset identifier is located near the top of the file (in the <head> section), normally as part of a line like:
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
In an e-mail message or newsgroup post, the charset identifier is part of the message headers; a typical example looks like this:
Content-Type: text/plain; charset=ISO-8859-1
In both cases the charset identifier is actually part of the Content-Type header, which—as you can see—contains other important information about the nature of the file.
It's important to keep in mind that Internet messages and web pages speak in terms of charsets rather than codepages. While the two terms may seem roughly equivalent, a charset is a standardized character encoding whereas a codepage is the specific implementation of one. So, while OS/2 may implement the ISO-8859-1 encoding as codepage 819, another operating system or software environment might use a different mechanism. (Indeed, as I mentioned back in Part 1, Windows 95 implements it as a subset of the more expansive codepage 1252; the Windows NT family uses Unicode for all text encoding which allows support for many different charsets simultaneously.)
However—under OS/2, at least—your software effectively does use the charset identifier to figure out what codepage to apply when displaying the file.
Encoding translation
I spent my last two articles discussing codepages at some length—in particular, how to display differently encoded documents by switching to the appropriate codepage. But there are a few problems associated with switching your codepage back and forth.
What I haven't yet discussed, however, is the other important use for codepages: as translation tables for actually converting one text encoding into another.
By converting I mean altering the data stream itself: translating characters in one codepage to the corresponding characters of another.
As an example, take the string I used back in Part 1:
We stopped for lunch at a café in Reykjavík.
Let's say we've received this text (in an email, perhaps) encoded in codepage 1252, but our system is currently set to codepage 850. With no intervention, the string will show up on our screen something like this:
We stopped for lunch at a cafÚ in ReykjavÝk.
Rather than achieve the correct display by changing the codepage to 1252 or 1004 (as we did back in Part 1), there are techniques available to actually convert this text so that it's correctly encoded for codepage 850.
If the original text is encoded for codepage 1252, the raw byte values look like this:
57 65 20 73 74 6F 70 70 65 64 20 66 6F 72 20 6C 75 6E 63 68 20 61 74 20 61 20 63 61 66 E9 20 69 6E 20 52 65 79 6B 6A 61 76 ED 6B 2E
In converting the text to codepage 850, the raw byte values are changed to:
57 65 20 73 74 6F 70 70 65 64 20 66 6F 72 20 6C 75 6E 63 68 20 61 74 20 61 20 63 61 66 82 20 69 6E 20 52 65 79 6B 6A 61 76 A1 6B 2E
The highlighted byte values are the ones that are changed (representing the non-basic-ASCII characters é and í).
If we display the string now, it appears correctly, even though—and this is the crucial point—we are still using codepage 850 for display.
What we've done is change the text to match the codepage; in a sense, this is the inverse of what we did in Parts 1 and 2, when we changed the codepage to match the text. Doing it this way instead has both advantages and disadvantages:
Advantages
- By converting text to the system codepage, it can be transferred between one program and another (using the clipboard, for example) without requiring every target program to switch its own codepage.
- You avoid the occasional OS/2 bugs inherent in switching the display codepage.
- Characters are capable of being displayed correctly even in text-mode sessions—as long as the current process codepage supports them.
Disadvantages
- The one major disadvantage is that characters which don't exist under the target codepage can't be converted, and are therefore lost. For example, Cyrillic characters don't exist under codepage 850, and so if you convert text which contains such characters, they are replaced by generic substitution symbols (usually the 'house' character, ⌂, although it depends on the codepage). Worse, there's no way to subsequently convert them back to the correct Cyrillic characters, because the old byte values are not preserved (unless the original data was saved separately).
So how do we actually perform this conversion? Well, that's normally something that has to be done at the application level: in other words, your web browser, email client, or newsreader is supposed to do it for you. That's the theory, anyway; of course, some applications are more intelligent about this than others.
Charset support in applications
This section takes a look at how a few specific programs measure up in terms of support for different charsets.
Mozilla
The various Mozilla products unquestionably have the best charset support of any Internet applications available to OS/2 users. Mozilla apparently handles, and renders, all text as Unicode; since Unicode, in theory, supports all character sets, characters should never be lost in conversion. And the massive development effort that supports Mozilla has ensured that its various products support as wide a range of different character encodings as you could possibly hope for.
With Mozilla support for different character sets is pretty much seamless. You may occasionally find a message or web page that fails to report its own charset properly in which case you might have to tell Mozilla what encoding to apply (via the View > Character Encoding menu, as described last time), but this is fairly uncommon.
Under Mozilla, you are effectively limited in charset support only by the fonts you use. Unicode-capable fonts are generally recommended (especially for the “Other Languages” category); the configuration of fonts under Mozilla was described in Part 2 of this series.
There is one potential stumbling block to keep in mind with Mozilla. To enable the full range of character support, the following must all be true:
- You must have the Innotek Font Engine installed.
- The correct Innotek registry entries for the Font Engine and all of the Mozilla applications must be defined in the registry under the HKEY_CURRENT_USER\Software\Innotek tree. Be careful of this, because the latest versions of the Font Engine do not create this tree by default (placing the entries underneath HKEY_LOCAL_MACHINE instead). You may have to add the correct values to the registry yourself.
- The following environment variable must be set:
SET MOZILLA_USE_EXTENDED_FT2LIB=T.
It is very easy to miss one or more of these; an incomplete configuration usually manifests itself as certain foreign-language characters (especially East Asian ones) being rendered as rectangles.
Pronews/2
The most recent versions of Pronews/2 are capable of handling a considerable range of different charsets. Unfortunately, understanding how all the pieces fit together can be a bit confusing.
Unlike Mozilla, Pronews does not change the display codepage when rendering text; instead (short of workarounds like CPPal), text must be converted into a single, predefined codepage—normally whatever codepage Pronews happens to be running under. (This is partly because Pronews relies more heavily on native PM controls, which suffer from certain limitations vis-a-vis codepage support.)
What Pronews does is conceptually straight-forward: it checks the charset of each article as you read it, then converts the article's text into the current codepage. Conversely, when posting, it interprets the posted article's text according to the current codepage, and converts it into whatever charset you have designated as active.
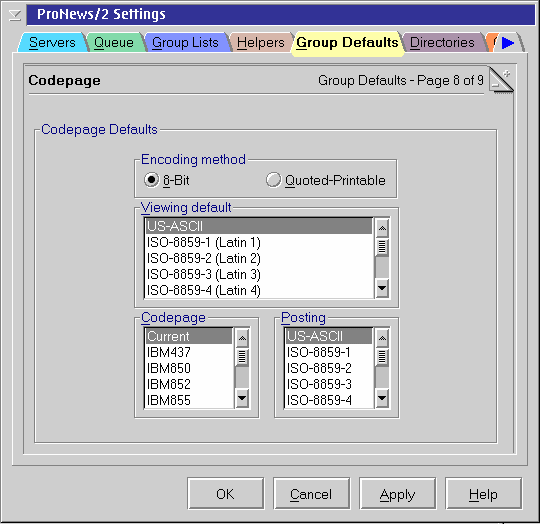
Figure 1: Configuring charset support in Pronews/2
This behaviour is governed by how you have certain configuration options set. These options are located on page 8 of the group settings (see Figure 1), and can be set either globally or on a per-newsgroup basis.
- Encoding method
- The Encoding method doesn't actually affect the charset; it simply indicates whether 8-bit characters are posted verbatim or using a simple encoding that renders them safe for 7-bit MTAs (which are very rare nowadays). In general, this can be left at the default setting.
- Viewing default
- Viewing determines how to interpret incoming messages that fail to report a charset. Such messages will be assumed to use whatever charset you select here; either “US-ASCII” or “Windows-1252” are usually good choices.
- Codepage
- The Codepage tells Pronews which codepage the text is converted into for display purposes (so that you can
read it properly). Normally, you should leave this at “Current,” which means that all text is
converted into the current display codepage (or from it, when posting).
If you select a different codepage, you might not read the text correctly; however, this could be useful if you want to copy and paste the text into (or from) some other application which uses a different display codepage.
- Posting
- Posting tells Pronews what charset you want all of your posted messages to use. Generally, you should choose a charset that supports all of the characters you are ever likely to want to use in a message. ISO-8859-1 or ISO-8859-15 are good choices if you only ever post messages in Latin-based languages; UTF-8 might be preferable if you anticipate the need for a wider range of languages.
It's important to keep in mind that you can only read—or post—text that is supported by the configured codepage. Any non-supported characters are converted into generic substitution symbols. Furthermore, if the configured codepage is not the same as (or at least compatible with) the current display codepage, non-ASCII characters are unlikely to appear in a readable form on your screen, although they should appear correct to whomever you are corresponding.
The latest release of Pronews actually allows you to modify the list of available charsets and codepages by editing some ASCII configuration files in the program directory.
- Your current codepage (under which Pronews runs) must be listed in the file CODEPAGE.PN—most common single-byte codepages are there already. (This file also determines which codepages are listed under Codepage in the Pronews settings, above.)
- For a charset to be supported, it must correspond directly to an existing OS/2 codepage. The charset name must be listed in the file CHARSET.PN, and the charset-to-codepage mapping must be listed in CPALIAS.PN.
Refer to the Pronews README.TXT file for more information.
PMMail/2
Version 2.x of PMMail/2 has fairly rudimentary charset support. It knows how to recognize a few common single-byte codepages (including 437, 850, 862 and 864) and a dozen common charsets (US-ASCII, KOI8-R, and ISO-8859-1 through -10). It uses the currently-active codepage to translate text to the selected charset when sending messages, and translates from the detected charset to the current codepage when viewing messages.
This works reasonably well when converting a single-byte codepage to a single-byte message encoding (or vice versa). However, it does not support many modern charsets (such as Windows-1252 or ISO-8859-15), and is inadequate to deal with multi-byte encodings (such as UTF-8, EUC, or Shift-JIS).
Fortunately, a major new version of PMMail/2 (now maintained by VOICE) will soon be released, and its charset support has been greatly improved and expanded.
In either version of PMMail, the basic logic is much the same. The global settings notebook has a page titled Locale (see Figure 2), on which you configure the default character set to use when sending messages.
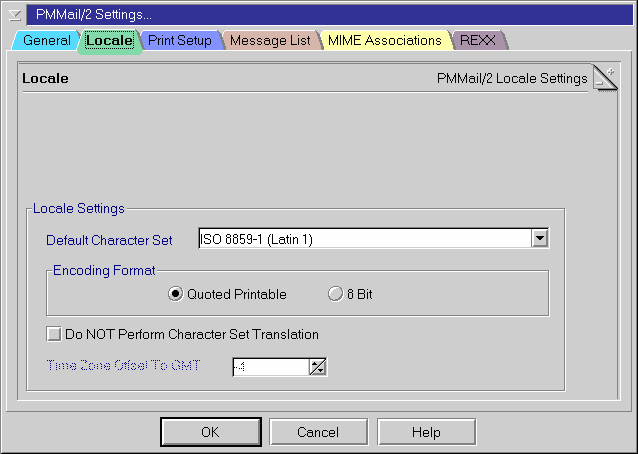
Figure 2: Configuring charset support in PMMail/2 (image from v2.20)
- Default Character Set
-
As mentioned, PMMail uses your selection to set the charset of outgoing messages.
(In PMMail version 3, this will also be used as a viewing default for incoming messages which fail to report their charset correctly; version 2.x simply defaults to US-ASCII if the charset is unknown.)
- Encoding Format
-
The Encoding Format is the equivalent of the Pronews “encoding method” setting. It indicates whether or not
non-ASCII characters are encoded for compliance with 7-bit mail relays.
Selecting "Quoted Printable" is usually the best option.
- Do NOT Perform Character Set Translation
-
This setting disables the translation between codepages and charsets, effectively causing PMMail to assume that
text being sent or displayed is already encoded correctly.
This option can be useful if you want to paste text into an outgoing message which is already encoded in the selected charset (but not in your current codepage).
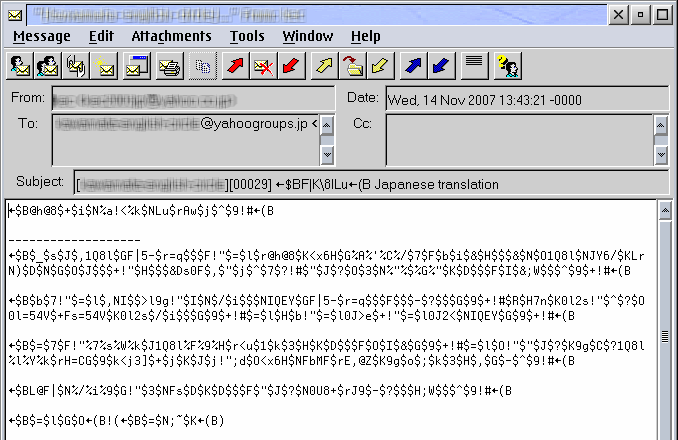
Figure 3: Unsupported Japanese text (charset ISO-2022-JP) in PMMail 2
Like Pronews, PMMail is limited to actually displaying the text in whichever codepage is currently extant. Again, this is because PMMail uses native PM controls, which are very limited in their ability to handle multiple codepages. In some circumstances, however, you can use the CPPal utility (as described in Part 1 of this series) to change PMMail's codepage before opening the message you want to view to read messages in a non-active codepage.
Figure 3 shows a typical example of Japanese-encoded text (using the common charset ISO-2022-JP), as it appears under PMMail 2.20—which does not support this encoding. (I've smudged out a few details for privacy's sake.) As you can see, it shows up as unintelligible gibberish. In this particular case, trying to change the codepage with CPPal or the equivalent won't help, because there is no codepage that implements ISO-2022-JP (it's a modal encoding based on escape sequences, and has to be specifically supported by the application).
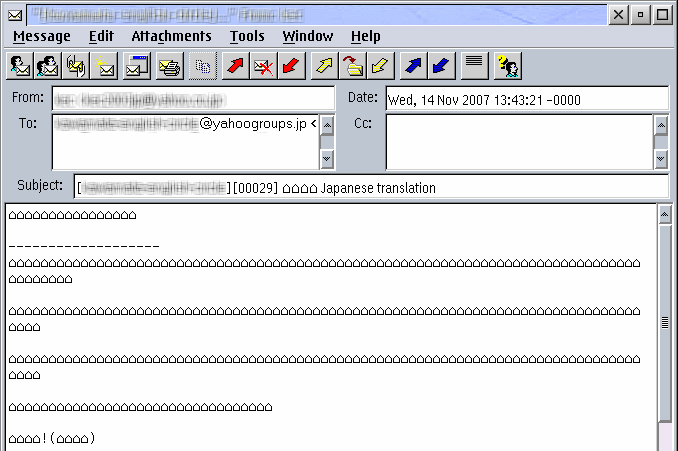
Figure 4: Supported but non-displayable Japanese text in PMMail 3
In PMMail 3.x, support for ISO-2022-JP (along with many other charsets) has been implemented, so this message's encoding should now be supported. However, PMMail still only displays Japanese characters if the current codepage supports it. Figure 4 shows what this message looks like under the new PMMail when using a non-Japanese codepage like 850.
Notice that all the non-supported characters have been replaced in the message display with the “house” symbol (⌂). This is the default substitution character for codepage 850, which I was using when this screenshot was captured.
The substitution character used in codepage conversion, and described above, should not be confused with the substitution glyph used by specific fonts, which was described in Part 1 of this series.
The codepage substitution character is, as the name implies, a function of the codepage. Its purpose is to represent a character which has a known value but which is not supported by the current codepage. The house (⌂) is most commonly used for this purpose, although a box (☐) a question mark, (?) or even the Unicode substitution character (�) may also be encountered. (It varies by codepage, and can also be overridden by the application.)
The font substitution glyph, on the other hand, is specific to the current font and cannot be overridden. It is used to represent a character which the font cannot display for some reason. (This may be because the font doesn't contain a glyph for that particular character, or because the character is inherently non-displayable, or even because the character value itself is illegal somehow.) “☐” and “�” are both commonly used, as are various nonsensical squiggles.
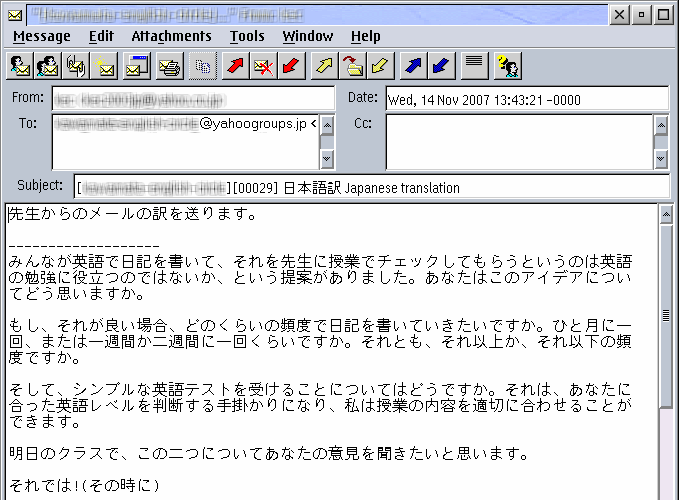
Figure 5: Supported and displayable Japanese text in PMMail 3
If I want to see the characters as the sender intended, I need to change the current codepage to something that supports them. Since I know the text is Japanese (which I can easily determine by looking at the message header to see what the specified charset is), I exit PMMail and restart it under a process codepage of 932, which is the OS/2 Japanese codepage. (If I wanted to switch to a single-byte codepage, I could simply use CPPal without shutting PMMail down; but, as I mentioned last time, switching from a single- to a double-byte PM codepage in this way doesn't work very well.)
Now, when I open the message under codepage 932—and make sure I have a Japanese-capable font available—I see the message as shown in Figure 5.
Note that the same issue applies (in reverse) when composing messages: you can only input characters which are supported by the current codepage. When you hit Send, your message text is converted into the charset which you have designated. Obviously, this means that you'd better choose a charset (a topic I'll discuss in a moment) which can support the characters you've typed!
This actually raises a more subtle pitfall which does exist. If, when replying to or forwarding a message, you quote text which includes characters that aren't supported by the current codepage, those characters are converted to substitution characters and lost. For instance, if (for some reason) I were to switch my codepage back to 850 and then reply to the message in Figures 3 through 5, any Japanese text I quote are converted back to substitution characters by the message composer. And, unlike incoming messages (where it only affects the display), character substitutions made in outgoing messages are permanent.
Basically, the rule is this: if you can read quoted characters correctly, they are preserved when you reply or forward (assuming you are using a charset that supports them). If you cannot read any characters correctly in the message composer—that is, if they appear as substitution characters—then they won't.
In short: always make sure you reply to a message under a codepage where you can read the original text correctly.
As I mentioned, the new version of PMMail should be released quite soon (in fact, it may well be out by the time you read this article). PMMail version 3 supports a wide range of charsets, including all the ones it supported before, as well as:
- UTF-8
- ISO-8859-11 (Thai/TIS-620), ISO-8859-13 (Latin-7) and ISO-8859-15 (Latin-9)
- Windows-1250 through Windows-1257
- ISO-2022 Internet message encoding for Japanese (-JP) and Korean (-KR)
- Shift-JIS (PC-style encoding for Japanese)
- Extended Unix Code (Unix-style encoding for Chinese, Japanese, and Korean)
- BIG-5 (Taiwanese)
Choosing a charset
All of the programs described above allow you to select the charset to be used in all of your outgoing email messages. (All of them provide global settings for this purpose; Mozilla and PMMail 3 also allow you to change the charset individually for every message.) All of them support a wide range of charsets, so the question immediately arises: which charset should you use?
This question can best be answered by considering two factors:
- What kind(s) of characters do you need to include in your messages? For example, if you need to send messages in Russian, then you'll have to use a charset that supports Russian text.
- What charsets can your correspondents (or, more specifically, their email software) handle? Obviously, this depends on their particular computer setup. Most modern email software can handle just about any charset you care to name, but if they're using something that's several years old there could be some compatibility problems. You may need to make educated guesses based on your knowledge of the people in question—or even discuss it with them if you anticipate problems.
If you were to consider point (1) by itself, then logically UTF-8 (Unicode) would be the best choice, since it supports virtually every possible character in almost all of the world's languages. However, not all email software is guaranteed to support UTF-8—indeed, PMMail 2.x (and earlier) is an obvious example.
Consequently, if you think this may be an issue with your correspondents, then an older and more widely-supported charset might be better. The principal disadvantage is that older charsets don't support as many different languages.
One of the oldest and most commonly-used charsets is the venerable ISO-8859-1 (discussed in Part 1 of this series), which covers most Western European languages and is supported by virtually every email application in existence. For messages in English, German, French, Dutch, Spanish, Italian, and the like, it should be a reasonably good choice.
Updates and Errata
Before wrapping up, I'd like to take the opportunity to provide some updates to points mentioned in my previous articles.
-
Back in Part 1, I mentioned a nasty OS/2 bug which can cause display of non-ASCII text to stop working throughout Presentation Manager after switching the display codepage a large number of times. This turned out to be a resource leak of some kind in PMMERGE.DLL, and IBM has now provided a fix. It applies to any OS/2 4.5x system (up to and including the last Convenience Package FixPaks), and is available to registered eComStation users as APAR PJ31908. (I'd like to thank Chuck McKinnis for patiently working with IBM to get this resolved—and, of course, to the folks at IBM for fixing it!)
-
KO Myung-hun's KShell program has been updated several times since Part 2 was published. The good news is that it now has (plain text) clipboard support, which significantly improves its usefulness. The overall stability seems to have improved as well. (The bad news is that recent versions don't seem to work well with the Innotek Font Engine anymore; but this isn't a show-stopper if you can find some decently hinted fonts.)
-
Finally, a quick correction to Part 1: I implied that the Unicode font Arial Unicode MS is part of Windows. In actual fact, it comes with MS Office (Office 97 and later), and is copied to the Windows font directory if certain Office language options are accepted for installation.
Closing Remarks
By now, I've pretty well covered the basics of using codepages to handle differently encoded text under OS/2. As you can see, it's always not as convenient a process as it should be, but you can usually manage to do most of what you need.
As I mentioned back in Part 1, the whole codepage system has one huge weakness, which is that it basically limits you to supporting only one (or at least only one non-English) character set at a time. Quite a number of years ago, the computer industry recognized this problem and came up with an intelligent solution: the Unicode standard.
As you may have noticed by now, a proper discussion of Unicode has been mostly absent from these articles so far. The reason is that Unicode support under OS/2, while it exists, is fairly obscure and largely dependent on the application. Consequently, it's more of a concern for programmers than for end users.
Nevertheless, there are some aspects of Unicode that it's useful for everyone to know. I'll write another article in the future that addresses some of them.